http://www.codebelief.com/article/2018/12/task-is-still-running-after-linux-shell-exits/
以在shell中执行ls命令为例,进行说明。
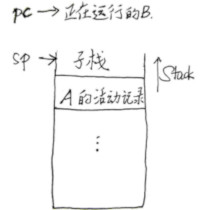
建立“子栈”的概念。从一个函数A跳转到另一个函数B时会创建一个临时堆栈,称函数A(调用者)所在的堆栈为父栈,称函数B(被调用者)所在的堆栈为子栈。调用者的活动记录被看为父栈的栈框架,代表着父栈的结束子栈的开始。
函数的活动记录按出栈顺序包括五个部分(真正能称为函数活动记录的只有2和3,故1-5称为栈框架更合理):
void
类型则没有该项记处于父栈环境的函数的活动记录为 \(S_0\) ,当向运行时栈压入 \(S_0\) 时便进入了子栈,当弹出 \(S_0\) 时便进入了父栈。在一个子栈中运行的基本框架如下所示:
pushl %ebp /*enter*/ //压入处于父栈环境的函数的活动记录
movl %esp %ebp
... //子栈环境
movl %ebp %esp /*leave*/ //恢复父栈环境
popl %ebp note:
push和pop都是依sp寻址的。
为深入理解该框架,要明确以下几点: * 首先要明确一个CPU在某一确定的时刻只能运行在一个堆栈空间中,当建立起子栈后,CPU便已运行在了子栈中,当前起作用的堆栈空间便是子栈,而当CPU离开子栈后,起作用的堆栈空间便成了父栈,且方才用过的子栈不复存在,即永远也不可能再次回到方才起作用的子栈,但能再次创建一个新的子栈。这也是将子栈称为临时堆栈、子函数的变量称为临时变量的原因。从根本上来看,除最初开机时建立的堆栈外,所有的堆栈都是临时堆栈,而子父关系便是相对而言。
其次由该框架可发现简易子栈与父栈在地址空间上是连续的,而若将子栈动态信息另存于系统中以实现再次寻回时(见正文),其框架只是加入了对子栈动态信息的保存和重载(因为子栈与父栈在地址空间上不再连续。而无法连续的原因是从子栈返回父栈后,子栈的数据极有可能被覆盖。所以连续的前提是确保子栈不会被第二次使用)。
最后要明确正文中的堆栈之间实际上不是父子关系,而是平等的。依然采用子栈、父栈的名称是为了结合该简易子栈的框架方便理解。依据时间顺序,称后创建的为子栈。
基本格式:
asm volatile(
汇编语句模板:
输出部分:
输入部分:
破坏描述部分
);
//即格式为asm("statements":output_regs:input_regs:clobbered_regs);常用寄存器加载代码说明: |代码|说明| |-|:-| |a|使用寄存器eax| |b|使用寄存器ebx| |c|使用寄存器ecx| |d|使用寄存器edx| |m|使用内存地址| |o|使用内存地址并可以加偏移值| |r|使用任意动态分配的寄存器| |+|表示操作数可读可写| |=|输出操作数,输出值将替换前值|
待续
若将之前所述的子栈的信息保存在系统中,便可实现在运行于某子栈环境中的进程退出前,总是能够再次找到该子栈。可采用类似于如下的结构实现子栈信息的保存:
struct Thread {
unsigned long ip;
unsigned long sp;
};由此,对于进程,可用如下结构进行描述:
struct PCB{
int pid;
unsigned long task_entry; //进程入口点
char stack[STACK_SIZE];
volatile long state;
struct Thread thread;
struct PCB *next;
};运行一个进程基本需要以下第三步:
asm volatile(
"movl %1,%%esp\n\t"
"pushl %1\n\t" //将0号进程栈底指针压栈
"movl %1,%%ebp\n\t"
"pushl %0\n\t"
"ret\n\t" //启动0号进程
:
:"c"(task[0].thread.ip),"d"(task[0].thread.sp)
);asm volatile(
"pushl %%ebp\n\t" /*保存父栈环境*/
"movl %%esp,%0\n\t"
"movl $1f,%1\n\t"
"movl %2,%%ebp\n\t" /*新建子栈环境*/
"movl %2,%%esp\n\t"
"pushl %3\n\t" /*启动x号进程*/
"ret\n\t"
:"=m"(task[NOW]->thread.sp),"=m"(task[NOW]->thread.ip)
:"m"(task[x]->thread.sp),"m"(task[x]->thread.ip)
);asm volatile(
"pushl %%ebp\n\t" /*保存父栈环境*/
"movl %%esp,%0\n\t"
"movl $1f,%1\n\t"
"movl %2,%%esp\n\t" /*切换栈环境*/
"pushl %3\n\t" /*切换至x号进程*/
"ret\n\t"
"1:\t" //下条指令的地址即为$1f对应的地址
"popl %%ebp\n\t" //此处pop出的是上次x进程被切换出去时push进去的ebp
:"=m"(task[NOW]->thread.sp),"=m"(task[NOW]->thread.ip)
:"m"(task[x]->thread.sp),"m"(task[x]->thread.ip)
);结合以上三点,便可总结调度器切换进程的简要步骤(省略进程的优先级策略等):
保存栈环境:进程断点压栈(编译器自动生成该指令),进程栈底指针压栈,保存进程栈顶指针,并保存恢复栈环境指令的首地址$1f。
转移栈环境:给栈顶指针赋值,并弹出新进程栈底指针和断点。
假设可执行文件是静态链接的(不考虑共享库),实例一个程序只需将程序的文本段、数据段、bss段和堆栈段映射到进程线性区,然后结合上述的第二点,调度到这个尚未创建栈环境的进程,之后只运行上述的第三点即可,从而便实现了对一个程序的实例化。
待续
refernece0: C语言ASM汇编内嵌语法zz
reference1: linux内核分析
进程是面向系统的,线程是面向cpu的,所以说,进程是资源分配的最小单位,线程是程序执行的最小单位。一个cpu核在某一个时刻只能执行某一个线程,通过时间片分片调度,便能通过多线程编程的方式提高程序运行效率。
由上可知进程、线程都是通过内核进行调度的,如果并发量太大,即使是线程,内核切换上下文的成本也太高,故引入协程的概念。协程:用户态级别的”线程”,对内核透明,也就是系统并不知道有协程的存在,是完全由用户自己的程序进行调度的,因为是由用户程序自己控制,那么就很难像抢占式调度那样做到强制的 CPU 控制权切换到其他进程/线程,通常只能进行协作式调度,需要协程自己主动把控制权转让出去之后,其他协程才能被执行到。
协程的底层实现和线程的原理是一样的,当 a线程 切换到 b线程 的时候,需要将 a线程 的相关执行进度压入栈,然后将 b线程 的执行进度出栈,进入 b线程 的执行序列,不过协程是在 应用层 实现这一点:对各种 io函数 进行了封装,这些封装的函数提供给应用程序使用,而其内部调用了操作系统的异步 io函数,当这些异步函数返回 busy 或 bloking 时,利用这个时机将现有的执行序列压栈,让线程去拉另外一个协程的代码来执行,基本原理就是这样,利用并封装了操作系统的异步函数。包括 linux 的 epoll、select 和 windows 的 iocp、event 等。
进程、线程、协程的对比如下:
进程的切换者是操作系统,切换时机是根据操作系统自己的切换策略来决定的,用户是无感的。进程的切换内容包括页全局目录、内核栈和硬件上下文,切换内容被保存在内存中。 进程切换过程采用的是“从用户态到内核态再到用户态”的方式,切换效率低。
线程的切换者是操作系统,切换时机是根据操作系统自己的切换策略来决定的,用户是无感的。线程的切换内容包括内核栈和硬件上下文,切换内容被保存在内核栈中。线程切换过程采用的是“从用户态到内核态再到用户态”的方式,切换效率中等。
协程的切换者是用户(编程者或应用程序),切换时机是用户自己的程序来决定的。协程的切换内容是硬件上下文,切换内容被保存在用户自己的变量(用户栈或堆)中。协程的切换过程只有用户态(即没有陷入内核态),因此切换效率高。