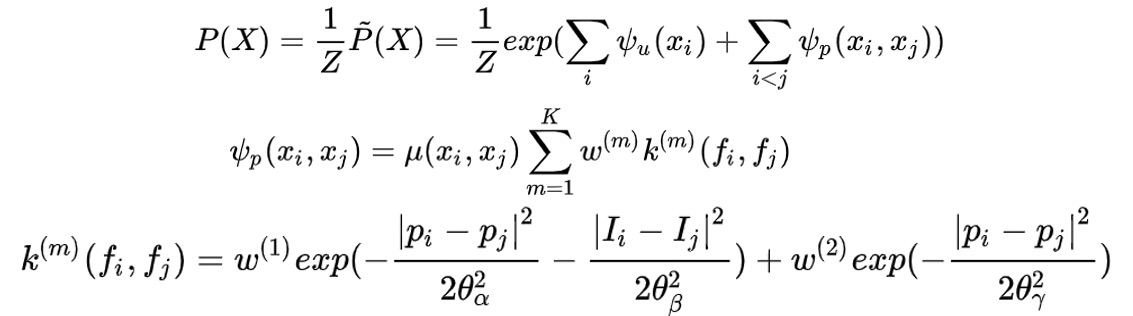
POS 是依据语法功能划分,是词语在区别词类时用到的属性。
rule-based
语言专家根据词法及语言学知识编制的规则。
learning-based
从专家标注的语料库中学习到用于自动标注的模型
| 符号 | 含义 |
|---|---|
| \(N\) | 训练数据中的句子总数 |
| \(O_i\) | 第 i 个句子(词序列) |
| \(o_i\) | 某句子中的第 i 个词 |
| \(Q_i\) | 第 i 个句子对应的词性标注(词性序列) |
| \(q_i\) | 某句子中的第 i 个词对应的词性 |
\[ \max_Q P(Q|O) \]
由于语料库不可能包含所有可能出现的句子,故为求解该模型,利用贝叶斯法则得等价模型 \[ \max_Q P(O|Q)P(Q) \]
生成模型是描述一个标签向量y如何概率的“生成“特征向量x的模型。判别模型致力于相反的方向,直接地描述如何对一个特征向量x赋予标签y。原理上,使用贝叶斯准则,每一种类型的模型都可以被转化为其他类型,但是实际上这些方法是有区别的。
\[ \max_Q \prod P(o_i|q_i) * \prod P(q_j|q_{j-1}), \]
其中\(P(o_i|q_i)\)被称为发射概率,是通过统计每个单词在语料库中的出现情况得到的。对于因某个单词没有在语料库中出现导致发射概率为 0 进而导致整个句子出现概率为 0 的情况,须做一些平滑处理。
解码问题即为搜索对于给定的一句话匹配度最高的一套tag。
对于给定的观测序列,求所有可能状态序列的概率,并将最大概率的状态序列最为所求结果。设观测序列长度为 T ,可选状态数为 M,可选观测数为 N,首先在最一开始时由初始状态概率向量 \(\pi\)求出后续 T-1 个状态概率向量\(i_t = \pi A^{t-1}\) ,那么一个可能状态序列的概率为,对一个句子的词性标注的时间复杂度为。
使用离散时间点、离散状态,并做了马尔可夫假设,由此系统产生了马尔可夫过程的模式,它包含一个\(\pi\)向量和一个状态转移矩阵。
隐马尔科夫模型是在一个标准的马尔科夫过程中引入一组观察状态,以及该组观察状态与隐藏状态间的概率关系。
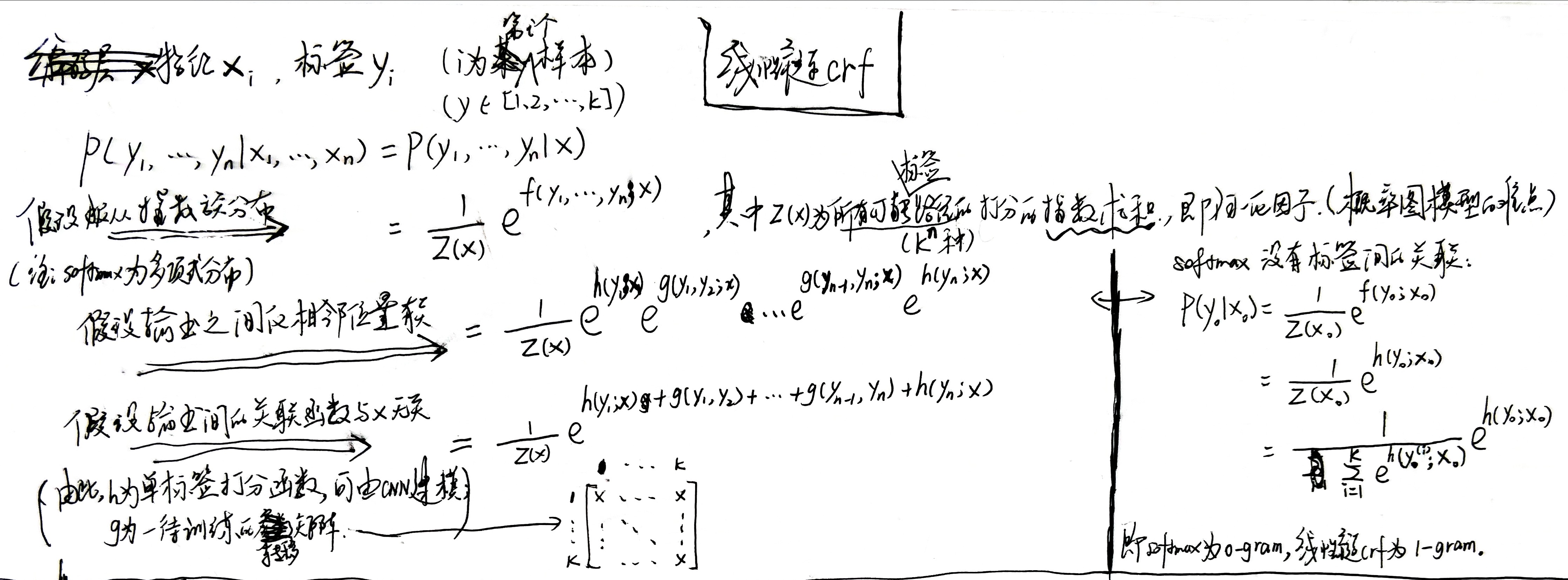
条件随机场是给定一组输入随机变量条件下另一组输出随机变量的条件概率分布模型,其特点是假设输出随机变量构成马尔可夫随机场。
对于有上下文关联的序列标注任务:用softmax的话是不考虑输出层面的上下文关联,而是把这些关联放到编码层面;用crf的话是将关联分离到输出层面,使模型学习更加容易(引入输出的关联,还不仅仅是 crf 的全部,crf 的真正精巧的地方,是它以路径为单位,考虑的是路径的概率)。
逐帧 softmax 和 CRF 的根本不同:前者将序列标注看成是 n 个 k 分类问题,后者将序列标注看成是 1 个 k^n 分类问题。
线性链CRF模型如下:
其中转移矩阵称为特征函数,为数据的先验知识,也可以用数据训练得到。特征函数的结果可以看作单标签打分函数(此处为任意的相邻两个)的权重。
模型loss为:

模型构建完成后,在输出端也是一个从 k^n 条路径中选最优的问题,因为一阶马尔可夫假设的存在,它可以转化为一个动态规划问题,用 viterbi 算法解决,计算量正比于 n。
softmax无法对像素点类别之间的关系进行建模(即每一个图像像素点的类别都有可能和临近点的类别相近),为对对像素点类别之间的关系建模提出denseCRF,如下:
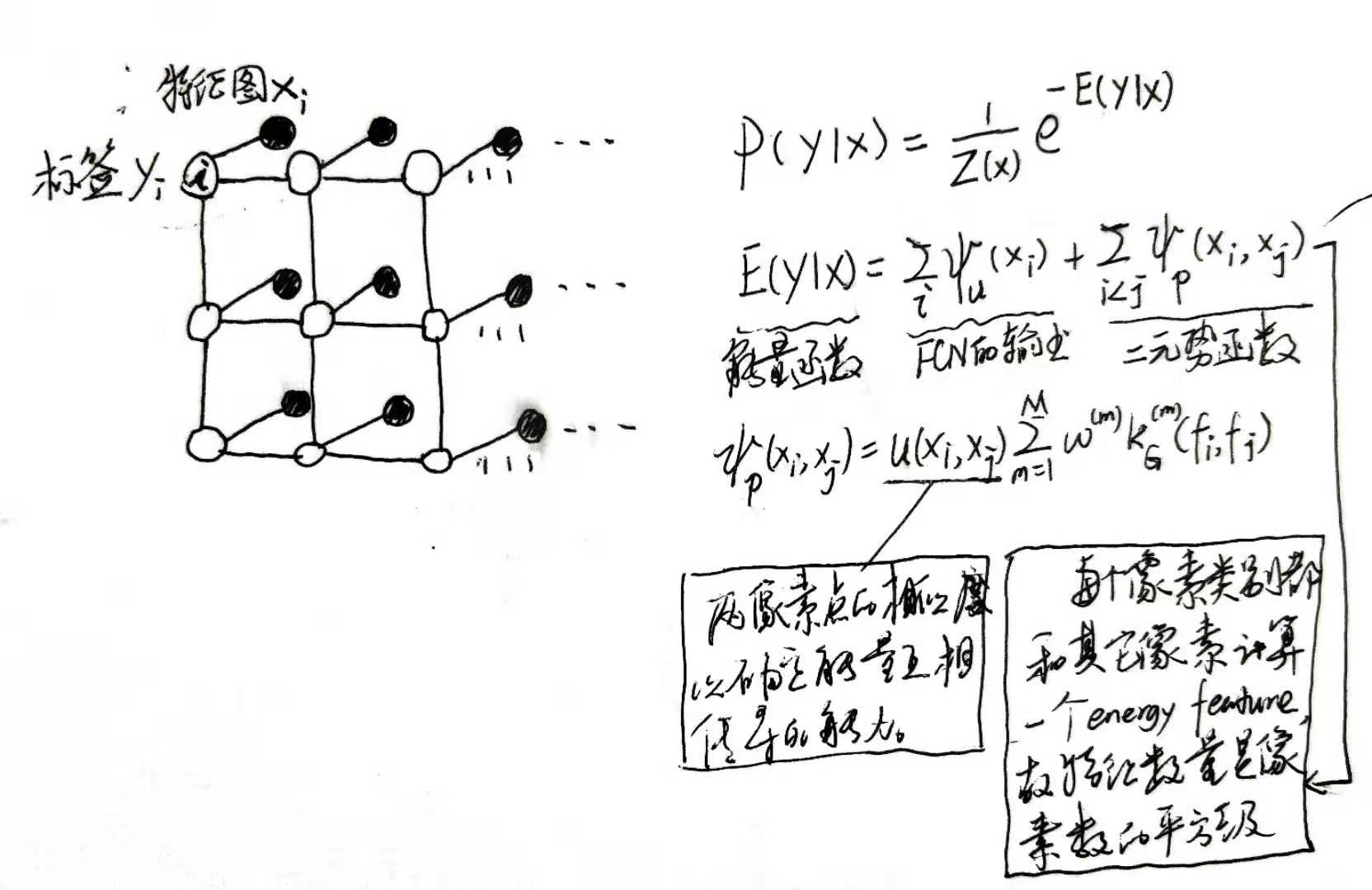
其中二元势函数就是描述像素点与像素点之间的关系,鼓励相似像素分配相同的标签,而相差较大的像素分配不同标签,而这个“距离”的定义与颜色值和实际相对距离有关。因为二元势函数描述的是每一个像素与其他所有像素的关系,所以叫“全连接”。具体公式如下: