若将计算机语言分类,有多种分类方式,最一般化的分类为 statically-typed(变量类型在编译时确定,并不再改变)和 dynamically-typed(变量类型在运行时确定,并可动态变化)两种,还有很多可以作为补充修饰的分类,如 strongly-typed, duck typing 等。cpp 为保证运行速度在编译完成后便确定了所有的数据类型,所以属于 statically-typed language。
cpp 也属于一种 duck typing。 cpp 提供了两种类型的多态,runtime polymorphism(基于虚函数实现)和 compile-time polymorphism(基于模板实现),分别为面向对象编程和泛型编程的基础。基于模板实现的编译时多态,可以认为是一种 duck typing,它不关心这些对象的类型具体是什么,只关心他们是否支持某些特殊操作。Duck typing 的好处是它可以将 API 和代码彻底解耦,大大提高了编码的灵活性。它不依赖于继承关系去做类型检查,它是在编译时做 duck test 实现类型检查的。因为它为保证运行速度,并不做运行时类型检查,所以只是一种 compile-time duck typing。相较完全的 duck typing 而言,cpp 的缺点自然是代码更加繁琐。
cpp 也属于一种 strongly-typed language,虽然丧失了灵活性,但提高了类型安全性,利于 debug。
分为
new,声明周期持续到delete)堆与栈结合的艺术:
float *p = (float *)malloc(sizeof(float)*100);,其中p的内存被分配在栈中,而其指向的那片动态申请的内存被分配在堆中,假如p移情别恋指向了别的地方(或者生命周期到了,死掉了),只要那片内存区域有人接管(或者说其地址有被保存下来),那就还能继续在那上面操作。const修饰符不能决定变量的存储区域,它只在编译时起作用。可以通过加static修饰符使得变量的存储区域强制为静态存储区,不过加了static修饰符后,虽然变量被放在了静态存储区,但它的作用域仍不是全局的,只在其对应的代码块中,如类的静态成员变量、某个源文件中的加static修饰的函数。在使用堆变量时,建议形成一下习惯:
new一片内存后,应立即检查指针值是否为NULL,防止在runtime时才报错(不完善的OS可能会直接宕掉)。类的声明与普通变量声明不同,类声明是一种类型的声明,它只声明一个类的“尺寸和规格”,并不进行实际的内存分配。
cpp规定在实例化一个对象时会生成6个默认的成员函数:无参构造函数,拷贝构造函数,
=重载函数,析构函数,&重载函数和& const重载函数。
this 实现);T * const this 改为 const T * const this
实现);new
一个结构体时后面接结构体类型,而 new
一个对象时后面不是接类类型而是接对象(因为需要知道调用的是哪个构造函数)):
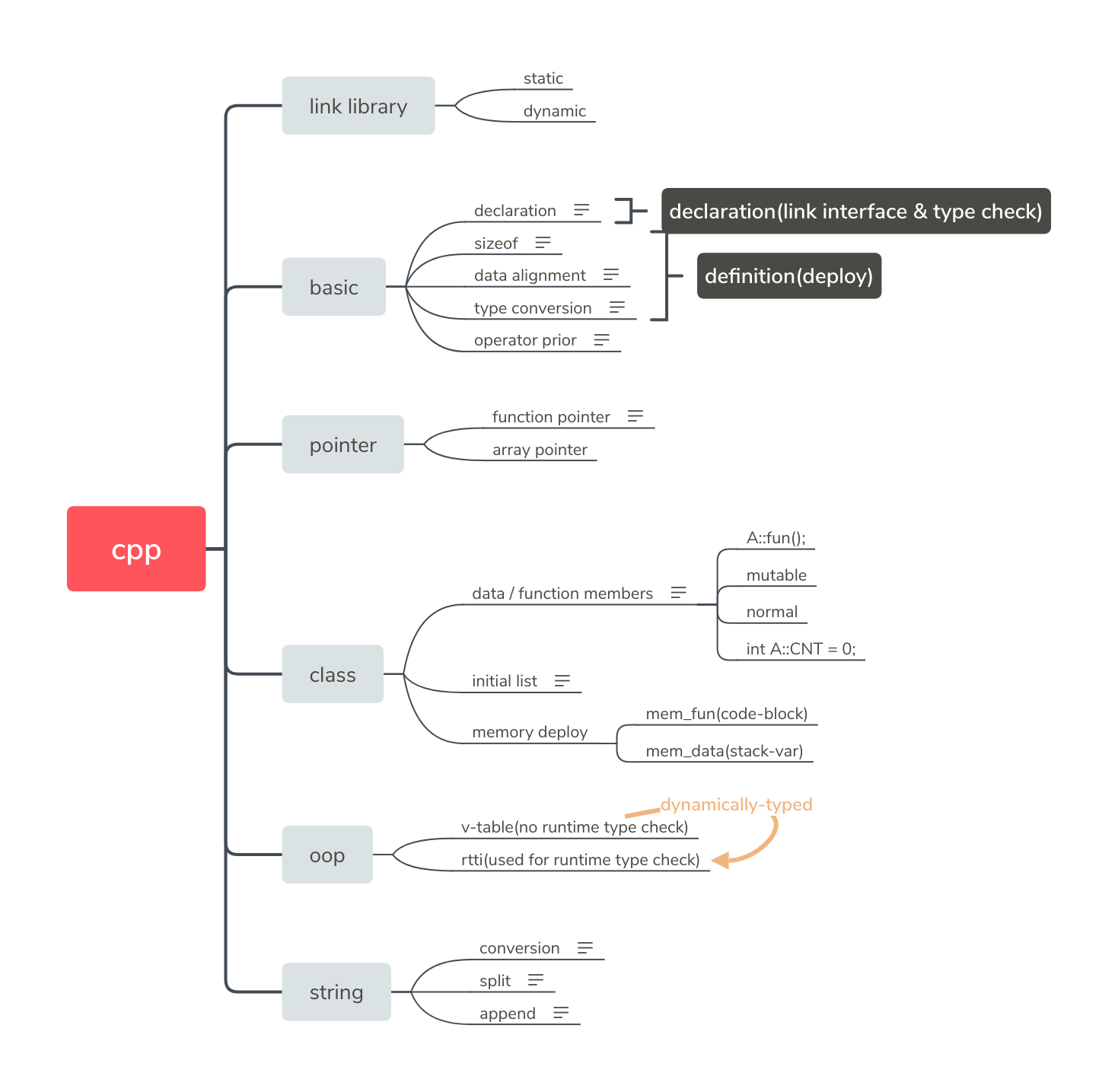
重载(overload)是处理同一个类中同名方法时出现的现象,多态(override,又称重写)是处理多个类(有公共基类)中同名方法时出现的现象。
实现方法:
重载的一种实现方法:编译器根据同名方法的不同参数表将同名方法重命名,从而成为一般的不同方法;
多态的一种实现方法:通过维护一个虚函数地址表,基类对象就可以根据当前赋值给它的派生类对象的特性以不同的方式运作;
基类对象的多态性是通过类的赋值兼容性实现的,而类的赋值兼容性是通过派生类实际内存分布实现的,故只有公有派生时才会有多态性;
动态绑定:只有当赋值为指针或引用类型时,才能知晓该指针(引用)指向的是哪个子类,进而才能利用虚函数技术,查询虚函数地址表,实现多态;而当赋给对象本身的拷贝时,只是内存的拷贝,没有RTTI,故无法实现多态;
抽象类:
函数指针需显示地声明输入输出参数类型来给编译器提供中断/恢复现场所需的信息 (否则即使解引用某个函数地址并后接括号,也无法正确调用该函数),且考虑到安全问题,不允许隐式的类型转换。函数指针存储的就是代码块的地址(该地址由编译器自动分配)。
与数组类似,函数名在作为一个值使用时会隐式地转换为指针,函数类型在作为形参使用时同样也会隐式地转换为指针。在使用函数指针调用函数时也会隐式地解引用(不要纠结函数地址解引用后是什么,记住解引用后的东西只用于后接括号这一种情况就好了)。为保证较好的阅读性,推荐如下的使用方法:
void (*pfunc)(void) = &func; // 显式地表明这是函数地址
pfunc(); // 统一规范函数调用形式,隐去编译器内部的繁琐操作另外,函数名代表的是那一段代码块,在编译时起符号链接作用,类似于变量名代表的便是那一个对象。
而类成员函数指针为能解决因为C++的多重继承、虚继承而带来的类实例地址的调整问题,在调用的时候一定要传入类实例对象,示例如下:
void (A::*pfunc)(void) = &A::func;
A a0 = new A();
(a0->*pfunc)(); //调用时必须要加类的对象名和*符号为了保证取到虚函数表的有最高的性能——如果有多层继承或是多重继承的情况下,编译器一般将虚函数表的指针存放于对象实例中最前面的位置。
当没有虚函数重载时,派生类的虚函数表为:虚函数按声明顺序放于表中,基类的虚函数在派生类的虚函数前面。
当有虚函数重载时,派生类的虚函数表中基类被重载的虚函数在原位置被覆盖,同时派生类的虚函数不再保留,其他的依旧。由基类指针所调用的虚函数名来静态确定在虚函数表中的偏移量,各派生类的虚函数表也在编译时静态生成;至于具体使用哪一个虚函数表,在运行时由基类指针的指向的具体内容决定。因为重载的虚函数是在基类的原位置覆盖,这就实现了多态。所以,早绑定是指要 call 的函数地址在编译期便被嵌入在了常量存储区(代码区),而晚绑定是指要 call 的函数地址是被放在栈中的,只有在运行时才能取到,也可以说是间接寻址。
注意,若仍然想在派生类调用基类中被重载的虚函数,可用域名解析符来调用child->Base::v_func(),如此编译器便不再走虚函数表,而是直接将函数地址插进来。
运行时多态可以看做为 dynamically-typed 的一种特性,它允许一个不知道具体类型的对象(但知道其基类类型)去调用一个只知道接口的函数,它与真正的 dynamically-typed language 不同,它通过虚函数表的技术在编译时实现类型安全检查。
若说继承的目的是代码重用,那么多态的目的便是接口重用。
类的一个特征是封装,public 和 private 用于实现这一目的;类的另一个特征是继承,protected 用于实现这一目的,其权限介于 public 和 private 两者中间,该访问权限下的成员只在整个继承树内可见,在外部不可见。
cpp所有的访问控制都是在语言级别实现的,而非内存访问逻辑级别。
| 成员变量修饰符 | 类外的普通函数 | public 派生类 | private 派生类 | protected 派生类 |
|---|---|---|---|---|
| public | 可以访问 | 可以访问(public) | 可以访问(private) | 可以访问(protected) |
| protected | 无法访问 | 可以访问(protected) | 可以访问(private) | 可以访问(protected) |
| private | 无法访问 | 无法访问(private) | 无法访问(private) | 无法访问(private) |
T&& 类型,类型 T
必须是通过推断得到的)。示例代码如下:
#include <iostream>
#define MALLOC (!0)
using std::cout;
using std::endl;
using std::cin;
// simulate memory block
class A{
public:
A() {}
A& operator= (const A& a) {
cout << "\tbuild A --memcpy" << endl;
return *this;
}
~A() { if(_pointer) cout << "\tremove A --free" << endl; }
int _pointer;
};
class B {
public:
B() : _id(++idProduce) {
cout << "\tbuild A --malloc" << endl;
_a._pointer = MALLOC;
cout << "\t...... constructor" << _id << endl;
}
B(const B& b) : _id(++idProduce) {
_a._pointer = MALLOC;
cout << "\tbuild A --malloc" << endl;
_a = b._a;
cout << "\t...... copy constructor" << _id << endl;
}
B(B&& b) : _id(++idProduce) {
b._a._pointer = 0;
cout << "\t...... move constructor" << _id << endl;
}
~B() { cout << "\t...... deconstructor" << _id << endl; }
int getid() { return _id; }
A _a;
static int idProduce;
private:
int _id;
};
int B::idProduce = 0;
void fun0(B b) { cout << "\t[RUN] fun0" << endl; }
void fun1(B& b) { cout << "\t[RUN] fun1" << endl; }
void fun2(B&& b) { cout << "\t[RUN] fun2" << endl; }
template <typename T>
void target_fun(T v) { cout << "\t[RUN] target_fun" << endl; }
template <typename T>
void test(T&& v) {
cout << "\t[RUN] test" << endl;
target_fun(std::forward<T> (v)); // v shouldnt be used after here!!
}
int main(void)
{
cout << endl << "# without move segmentic" << endl;
cout << "* situation 1(Lvalue copy)" << endl;
B b1;
fun0(b1);
// delete &b1; //core dump due to b1 is on stack not heap!!
cout << "* situation 2(Lvalue reference)" << endl;
B b2;
fun1(b2);
cout << endl << "# use move segmentic without the help of Lvalue" << endl;
fun2(B());
cout << endl << "# perfect forward" << endl;
cout << "* situation 1(Lvalue copy)" << endl;
B& b3 = *(new B());
test(b3);
delete &b3;
cout << "* situation 2(Rvalue)" << endl;
test(B());
cout << "* std::move" << endl;
B b4;
test(std::move(b4));
}运行结果为:
# without move segmentic
* situation 1(Lvalue copy)
build A --malloc
...... constructor1
build A --malloc
build A --memcpy
...... copy constructor2
[RUN] fun0
...... deconstructor2
remove A --free
* situation 2(Lvalue reference)
build A --malloc
...... constructor3
[RUN] fun1
# use move segmentic without the help of Lvalue
build A --malloc
...... constructor4
[RUN] fun2
...... deconstructor4
remove A --free
# perfect forward
* situation 1(Lvalue copy)
build A --malloc
...... constructor5
[RUN] test
build A --malloc
build A --memcpy
...... copy constructor6
[RUN] target_fun
...... deconstructor6
remove A --free
...... deconstructor5
remove A --free
* situation 2(Rvalue)
build A --malloc
...... constructor7
[RUN] test
...... move constructor8
[RUN] target_fun
...... deconstructor8
remove A --free
...... deconstructor7
* std::move
build A --malloc
...... constructor9
[RUN] test
...... move constructor10
[RUN] target_fun
...... deconstructor10
remove A --free
...... deconstructor9
...... deconstructor3
remove A --free
...... deconstructor1
remove A --freehttp://wiki.baidu.com/display/GR/coding+best+practice#codingbestpractice-1.%E7%A6%81%E6%AD%A2%E4%BD%BF%E7%94%A8std::ostringstream%E3%80%81boost::lexical_cast%E3%80%81std::stoi%E7%AD%89%E7%B3%BB%E5%88%97%E5%87%BD%E6%95%B0
http://wiki.baidu.com/pages/viewpage.action?pageId=321387207#id-%E9%9D%99%E6%80%81%E5%88%86%E6%9E%90%E4%B8%BB%E9%A1%B5-feed-fork-9
指针声明时建议为 T *var ,而引用声明时建议为
T& var
。这种形式正体现了这两种类型的区别与应用场景:
* 与 var
自然应绑定在一起,放于中心词该在的位置var ,故 & 应与
T 放在一起在代码块中引用没有存在的意义,直接使用 T
类型的变量即可;在函数的参数列表中依实际场景选择采用指针还是引用。
childObject.ParentClassName :: fun() ;