阅读量 ,评论量
Doing
https://hrl.boyuai.com/chapter/intro
https://karpathy.github.io/2016/05/31/rl/
基础
策略梯度定理推导:
常见模型
Q-learning
用一个表格(Q表)记录在不同状态下采取各个动作所能得到的潜在回报。
这一算法的关键是学习的目标设置:将『采取该行动后得到的奖励 +
采取动作后的新状态下的最大Q值(无论将来再采用哪种动作)』作为在原状态下实施对应行动后的Q值的目标值,即,\(r_{s\_new} + \gamma Q_{s\_new}\)。
- 第二项为什么要用『采取动作后的新状态下的最大Q值』:
- 本质是模型使用方式决定的。因为模型在最终使用时,输出的动作就是对应Q值最大的。从最终状态往前倒推,实施的即为一串Q值最大的动作序列,为保证模型从任一状态开始都能最大概率地导向最优状态,设计某一状态下任一动作的Q值时,便需要将后续大概率采取的一系列动作也考虑进来。
| s |
当前状态 |
| a |
动作 |
| Q表 |
在各个状态s下采取各个动作a得到的Q值组成的表 |
| Q(s0, a0) |
在状态s0下采取动作a0得到的Q值 |
| Q(s0) |
在状态s0下采取某个动作a所能得到的最大Q值 |
| r |
奖励,通过设置不同状态对应不同奖励从而求得任务所需的Q表 |
Q表更新(学习)规则: \[
Q_{s_0, a_0} = Q_{s_0, a_0} + \alpha [(r_{s_1} + \gamma Q_{s_1}) -
Q_{s_0, a_0}]
\] 其中 \(\gamma\)
为未来奖励的衰减率,\(\alpha\)
为学习率,对其做递归展开得(设 \(\alpha =
1\) ): \[
\begin{align*}
Q_{s_0, a_0} &= Q_{s_0} \\
&= r_{s_1} + \gamma Q_{s_1} \\
&= r_{s_1} + \gamma (r_{s_2} + \gamma Q_{s_2}) \\
&= r_{s_1} + \gamma r_{s_2} + \gamma^2 r_{s_3} + \dotso
\end{align*}
\]
故 \(\gamma\)
越大,对未来考虑越多。
详见demo(treasure_on_right)
。
Deep Q-learning(DQN)
用神经网络来实现Q表的功能,解决状态取值为连续值的问题。
将采取动作后的回报值作为DNN预估值,相当于多个目标的回归任务,目标个数即为全部的动作个数。
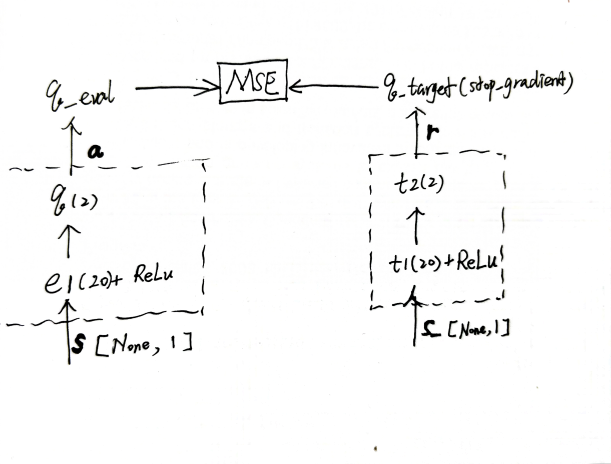
训练细节:
- fixed Q-targets:可以理解为右边的网络是左边的镜像,但只在每 200 个
batch 后才做
target_replace_op(将左边的网络参数更新进右边的网络中),避免label分布变化频繁,从而保证稳定收敛。通常称右边的网络为target_model,左边的网络为online_model。
- 经验回放:每 5 步做一次学习,大前提是已做了至少 200
步的仿真(记忆库最大容量设为 2000,每个 batch 是从记忆库中随机挑选的)
- 使样本满足独立假设(非独立同分布的数据对训练神经网络有很大的影响,会使神经网络拟合到最近训练的数据上,即容易出现某种维度上的过拟合,导致泛化性变差)。在
MDP
中交互采样得到的数据本身不满足独立假设,因为这一时刻的状态和上一时刻的状态有关,采用经验回放可以打破样本之间的相关性,让其满足独立假设。
- 提高样本效率。每一个样本可以被使用多次。
- epsilon-贪婪策略、玻尔兹曼策略:TODO
详见demo(DQN/run)
。
Double DQN
理论上来说,DQN的设计会天然存在Q值高估问题:本质是DQN设计的label计算逻辑导致的正向误差累积。
可以从任一状态开始往前倒推来理解。假设在某一状态下采取任一动作后的Q值均为0(或者相差无几),若target_model在某一动作上存在微弱高估,执行max操作后,\(r_{s\_new} + \gamma Q_{s\_new}\)
即为偏高的label,online_model可能会估得偏低可能会偏高,估得偏低时不会出现什么特别的影响,而一旦估得比偏高的label更高时,执行target_replace_op后,target_model也会估得更高;状态往前推,因为通过max操作选label,高估的信息便会继续往前传递,逐渐累加。对于动作空间较大的任务,DQN
中的过高估计问题会非常严重,造成 DQN 无法有效工作的后果。
实际表现会是什么样子:TODO(模型输出的Q值出现大于预设分布最大值的情况?这又怎么影响实际应用的有效性的呢?)
Double
DQN的解决方案:在计算label时,max操作和Q值操作不用同一个网络(target_model),而分别用两个网络(max用online_model,Q值用target_model),从而缓解正向误差累积问题。
Prioritized Replay DQN
Dueling DQN
有很多任务,在部分场景中,Q值只受当前状态影响,无论采取什么动作,期望回报区别不大。比如避障任务中没有障碍的场景,承接条数识别任务中承接与否无所谓的用户。
模型预估两部分,价值函数V(不考虑动作,可以理解为预估的是在某一状态下采取任一动作后Q值的均值),和优势函数A(预估的是在某一状态下采取该动作后的Q值
相较于 采取任一动作后Q值
的优势)(若样本为动作a1,该样本是否更新其它动作对应的优势函数部分?)。即将原目标
\[
Q^{online\_model}_{s} = r_{s\_new} + \gamma
\max{Q^{target\_model}_{s\_new}}
\] 中的Q值计算改为两个输出值的计算: $$ Q^{online_model}{s} =
V^{online_model}{s} + A^{online_model}_{s} \
Q^{target_model}{s_new} = V^{target_model}{s_new} +
A^{target_model}{s_new} \[
对于建模不唯一性的问题(对于同样的Q值,如果将V值加上任意大小的常数C,再将所有A值减去C,则得到的Q值依然不变,这会导致训练的不稳定性),通过在计算Q值时再减去一项优势函数的最大值,从而调整最优动作的优势函数值为0,由此确保V值建模的唯一性=max(Q)(TODO
有待理解。。。):
\] Q^{online_model}{s} = V^{online_model}{s} +
(A^{online_model}{s} - ) \
Q^{target_model}{s_new} = V^{target_model}{s_new} +
(A^{target_model}_{s_new} - ) $$
另外,通过用两个目标的方式来去学习也可以解建模不唯一性的问题(待尝试)。
价值函数: \[
V^{online\_model}_{s} = td\_target
\] 和优势函数: \[
A^{online\_model}_{s} = td\_target - V^{online\_model}_{s}
\] 其中 $$ td_target = r_{s_new} + \
Q^{target_model}{s_new} = V^{target_model}{s_new} +
A^{target_model}_{s_new} $$
这里td_target依然采用max的方式去做,会不会有问题?
Policy Gradient
DQN
状态可以达到无限,但输出的是已设定的各个动作的Q值(潜在回报值),故动作数量依然是有限的(有几个输出神经元便是所能采取的动作数量);通过直接输出动作的值而不是某个动作后的回报值的方法,可使得输出动作达到无限,这种方法称为
Policy Gradient。
通过奖励的设置,来去改变回传的梯度的大小(也可以理解为label的置信度),这也是叫PG的原因。
与DQN的本质区别:DQN学的是各个动作后的回报值,PG学的是下一个动作(动作取值
如移动的偏移值,或
动作id的概率)。即如果都是面对离散动作空间的话,PG是在解分类问题,DQN是在解回归问题(类比
PG在做时长满意分类,DQN在做观看时长回归)。
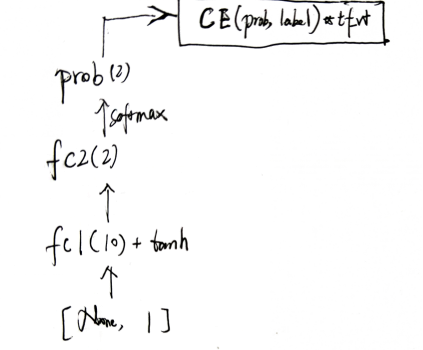
因为label是直接用的模型输出的action,所以为了避免每条样本的CE都是0,实际操作时选用label的action会引入随机。
与DQN更新的策略不同,DQN可以单步更新参数,而PG只能回合更新。因为虽然label引入了随机,但CE的期望值依然是0,只能用奖励修正loss的期望,故PG只能回合更新(若没完成回合,则所有的动作奖励都是0;除此之外,若即使有奖励值来去修正,但不是同一个回合的样本的话,也会因为随机抽取样本,样本分布发生变化(比如奖励低的资源异常地多),导致效果变差)。
PG方差太大,lr正常设置容易无法收敛,lr往小里设置收敛太慢(PG为啥方差会很大?)
详见demo(RL_brain/demo)
。
Actor Critic
对PG中用于修正loss期望的奖励,用DQN来预估,这样就能解决PG只能回合更新的问题了。PG称为Actor,DQN称为Critic。
Critic的引入为什么能够减少PG的方差?
判断离线模型有变好的指标:
- 相同动作次数的样本窗口下,reward(不是累积奖励,而是即时奖励)之和,需要与环境交互收集、或者有RewardModel来评估
- 策略熵
DDPG
为了继续用DQN的off-policy,且能应对连续action的任务。
相较于DQN主要有三个改动:
- 因为是连续action,没法比较多头的Q值,选最大action的Q值作为target;故采用state和action都为模型输入的DQN,并新增加一个在给定状态下输出能产生最大Q值的action的网络。
- 目标网络采用软更新的方式,而不是延迟更新的方式。
- 相较于DQN没有概率输出了,为了提高探索能力,引入随机噪声。
PPO(Proximal Policy
Optimization)
PPO 利用 New Policy 和 Old Policy 的比例,限制了 New Policy
的更新幅度,让 Policy Gradient 对稍微大点的学习率不那么敏感。
PPO的关键就两点:
- 通过重要性采样调整每个样本的权重(等价于调整action的分布),从而实现不依赖重新采样新数据的情况下进行策略更新;
- 快模型输出截断,从而实现快模型的更新不偏离慢模型太多(等价于置信区域);
https://zhuanlan.zhihu.com/p/28223597805
标准PPO
以『倒立摆』为例。
训练流程:
- actor有两个模型,快慢模型,慢模型用来产出样本,快模型训练10个epoch后将参数更新到慢模型上。
- 每个epoch训练时,actor的loss在回传梯度时不更新critic部分。在快模型将参数更新到慢模型上后,critic模型再训练10个epoch。
- 之所以actor在训练时采用上一个版本critic预估(Rollout →
Reward → Values(旧版本Critic Forward) → Advantage → Critic Update &
Actor
Update)的方式,而不是新数据分布下拟合的critic(Rollout
→ Reward → Values(旧版本Critic Forward) → Critic Update →
Values(新版本Critic Forward) → Advantage → Critic Update & Actor
Update)的原因有两个:
- 若critic
不过拟合新数据分布,一个pass的训练数据,对critic预估效果的边际效益很低,对critic预估精度影响不大,而额外增加一次全量数据的forward徒增训练耗时;
- 若critic 过拟合新数据分布,易导致 advantage
幅度坍缩,从而使得训练样本没有了优势轨迹信号,actor
难以收敛;(本质的原因是ValueModel需要的均值预估能力,而非在新数据分布下估得多准)
- 旧版本Critic Forward不能合并进Critic
Update的原因是,在训练时每次mini_batch都会改变critic模型参数,导致Values方差过大,影响Actor收敛,故需要一次额外的全量数据的no_grad
forward;
- 每个epoch训练完后所有tensor的梯度都重置成None(这个操作的原因是啥?)
样本收集:
- 由上次样本的next_state作为本次的state(若没有则随机初始化一个state),慢模型根据输入的state输出动作取值的分布(均值&方差)(常规的模型相当于只输出了均值),随机采样得到动作取值actionx。并根据env计算执行动作后的reward和next_state,由此产出一条样本:state,
actionx, reward, next_state, done
备注:
- 快慢模型设计的原因是,需要有一个与env交互产生样本的东西,相当于将env视为黑箱,需要一个探测器从各个不同的点位试探出来一些不同的反馈信号,借此逆向出一个可用的(与env交互的)agent来。探测出来的反馈信号也决定了agent的性能,所以在训练过程中也要逐步更新慢模型。
critic
\[
loss = \text{MSE} (\text{CRITIC}(state), td\_target)
\]
\[
其中,td\_target = reward + 0.9 * \text{CRITIC}(next\_state) * (1 -
done)
\]
- td_target
是带衰减的累积奖励,其中reward是状态走到next_state后的奖励
- critic模型只有状态值的输入,故可以认为critic预估的是
在输入状态下执行任一动作后获得的累积奖励的均值
- 『倒立摆』任务中,reward值域为(-1.0342, 1]
actor
\[
loss = -\min{[A * ratio, A * ratio|^{1.2}_{0.8}]}
\]
\[
\begin{align}
其中,& ratio = \frac{p_{actionx}}{p_{actionx}^{old}} \\
& A = td\_delta + 0.9 * 0.9 * A_{next} \\
& td\_delta = td\_target - \text{CRITIC}(state)
\end{align}
\]
- loss的设计即为希望梯度回传让模型找到在状态state上时采取哪个actionx时能够最大化A
- 通过clip+min的操作实现如下效果的截断(前提是ratio为单调递增的):
- A>0时,值域限制到[A * lower, A * upper]
- A<0时,值域限制到[A * lower,
+inf](这里的+inf便是min操作的价值,保证A<0且高估时加大削弱力度)
- 非对称CLIP的原因:
- 其它截断自然是避免新策略偏离旧策略太远了,这里主要解释+inf的情况。+inf自然是指新策略给某一动作的概率远大于旧策略,那么只会有两种情况:
- 旧策略给该动作的概率非常小(比如0.001):这种情况下如果不暴力拉回,而是做截断,势必导致状态过度漂移,新策略下次rollout的样本不可用,最终训崩。
- 新策略给该动作的概率过大(比如0.999):这种情况下如果不暴力拉回,而是做截断,势必导致策略过早塌缩,在该状态下发生梯度弥散,最终影响收敛效果。
- 一般upper定位为鼓励探索的力度,使得对某些动作的概率远高于旧策略:
- 啰嗦解释:所谓鼓励探索,是指想办法更大力地将某些概率极低的动作变高;如果两个动作具有相同正优势值和相同\(p_{actionx}\) , \(p_{actionx}^{old}\)
偏低的动作对应的ratio便会更大,那么将upper调高会使得 \(p_{actionx}^{old}\)
偏低的动作对应的loss更大,即等价于更倾向于强化 \(p_{actionx}^{old}\) 偏低的动作;
- 方便记忆的解释:原先几乎采样不到的动作,如果有巨大的正优势信号灌进来,可以尝试让新策略更多地提高采样到它的概率,从而避免策略过早塌缩;
- lower定位为保护不太偏离已有策略,避免衰减过量:
- 啰嗦解释:要想触达lower,自然是一个动作在新策略上的概率低于旧策略,要想走到这一步,自然是这个动作的优势值大部分都是负值,从而使得新策略在该动作上的概率越来越低,其它动作上的概率自然会越来越高(默认policy模型是softmax模型),如果不加限制,那么新策略将几乎不再采样该动作,且会加大其它随机动作被采样到的概率,最终会非常偏离旧策略采样出来的分布;
- 方便记忆的解释:原先能采样到的动作,即使有成堆的负优势信号灌进来,依然要尽可能地保证新策略也还能采样到,可以概率降一点,从而避免状态过度漂移;
- 其中,A:
- A已从计算图中分离,故可认为是常量,优化器只能通过改变ratio来降低loss,即通过改变ratio的分布来将所有样本的A*ratio的均值最大
- 若优势函数为负值,则降低ratio,若优势函数为正值,则增大ratio;A的绝对值越大,降低/增大ratio的幅度便会越大
- 因\(p_{actionx}^{old}\)为慢模型的输出值,也可认为是常量,故:
- 优势函数为负值时,优化器将会降低\(p_{actionx}\)(mu远离actionx,增大std),越负降低的幅度越大;
- 优势函数为正值时,优化器将会增大\(p_{actionx}\)(mu靠近actionx,减小std),越正增加的幅度越大;
- td_delta为时序差分误差,含义为在状态state下执行动作actionx得到的累积奖励比执行任意动作高/低多少
- 为简化逻辑,可先暂时不考虑优势函数的累积,则优势函数A即为时序差分误差
- 其中,ratio:
- 计算ratio的p是actor模型输出的动作值为actionx时的概率
- ratio只要满足下面两条性质,怎么设计都可(只是有训练效果的差异,根据具体任务具体改):
- A正得越大,快模型的输出越逼近样本的action,A负得越大,快模型的输出越远离样本的action
- 随着训练的过程,快模型输出的分布将会发生变化,使得所有样本的A *
ratio(或者A * p)的均值逐渐趋于最大
- 在每次快慢模型的actor同步后,所有样本的ratio应该都几乎是1,但A是新的critic模型的预估值(按理应该更准),A的分布将会发生变化,故随着训练的过程,ratio分布也将会发生变化,使得所有样本的A*ratio的均值逐渐趋于最大;该过程循环往复,最终收敛到最优状态。
- 重要性采样:
- 称ratio为重要性采样项,将慢模型的采样数据重新加权,匹配新策略,从而能够在不依赖重新采样新数据的情况下有效利用已有数据进行策略更新(即同份数据训练10个epoch)
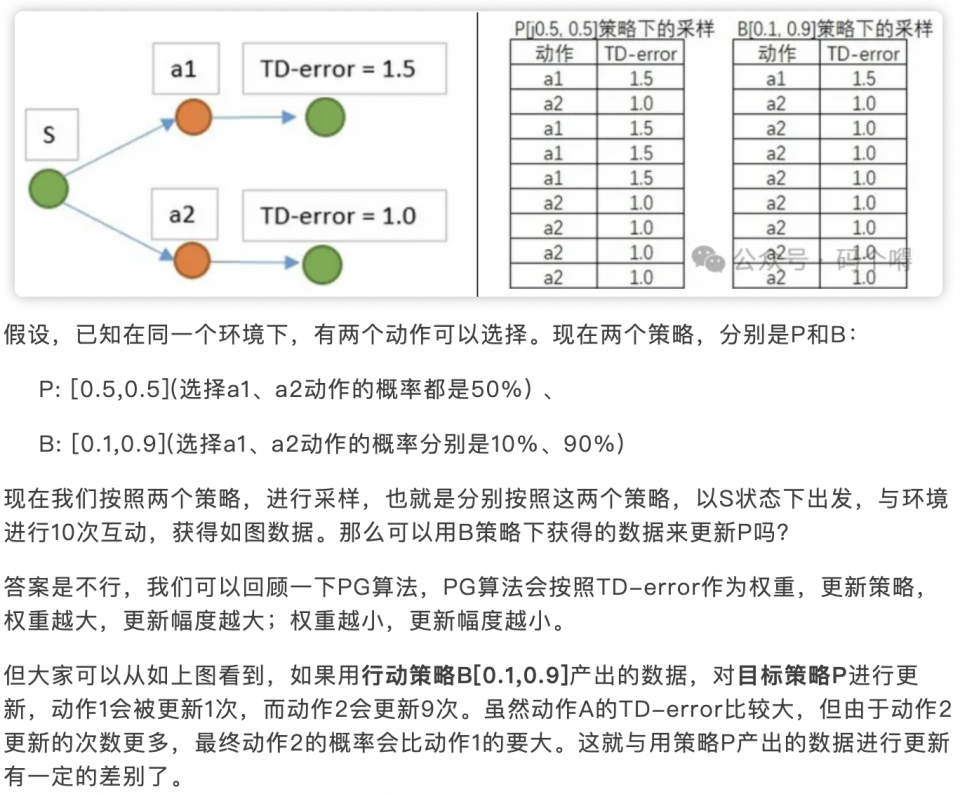
- 对于原始的policy-gradient损失函数为(\(A *
\text{CE}(\hat{action},
actionx)\));样本由慢模型产出,所有样本的优势值的分布是由慢模型采样出来的,因为采用mini-batch的方式更新模型参数,所以样本的分布会很影响模型收敛效果,即直接用慢模型的产出将会使得快模型更多地去拟合采样出来的数量更多的动作,而非优势值更高的动作,这会严重影响模型收敛速度,更甚至会让模型无法收敛(这件事情本质上是快慢模型的采样训练流程导致的,而非损失函数导致的;所以原始PG的可用性需要辩证地去看):
- 此外,A:
- 优势函数的估计有两种方式,这里用的是时序差分法估计。另外还有蒙特卡洛法估计:
- 蒙特卡洛方法通过对完整的轨迹进行采样,执行动作actionx后,用实际的回报来估计价值函数。即A
= R(state, actionx) - CRITIC(state),其中R(state,
actionx)是采样的实际回报,也就是从执行动作actionx开始到一个完整回合结束后的累积reward。
- 该方法缺点是方差较大,因为单次采样可能会受到偶然因素的影响,估计结果可能不稳定。
- 时序差分法方差较小,因为它依赖于多个小步的估计,平滑了每一步的波动。但该方法由于使用了估计的价值来更新,可能会引入一些偏差。因此,两种估计方法的选择是在偏差和方差之间的权衡。
- 由此引入广义优势估计,定义如下。其中,λ
为平衡偏差和方差的系数,λ=1时,GAE退化为蒙特卡洛方法,方差较大但无偏,λ=0时,GAE退化为时序差分方法,偏差大但方差较小;γ
为后续价值的衰减系数。
\[
A = reward + \gamma\text{CRITIC}(next\_state) - \text{CRITIC}(state) +
\gamma * \lambda * A_{next}
\]
数值稳定性问题
重要性采样ratio常用log空间操作,以保证数值稳定性: \[
r_t(\theta) = \frac{\pi_{\theta}(a_t|s_t)}{\pi_{\theta_{old}}(a_t|s_t)}
= \exp(\text{new_log_prob} - \text{old_log_prob})
\]
这里的log_prob需要注意的是,new和old的精度一定要保证一致,否则会出现致命的系统偏差:
- fp16 的尾数只有 10 bit,fp32 有 23 bit。对于一个 -3 左右的 log_prob
值,fp16 存储后误差约有 0.001;对于一个 -10 左右的 log_prob 值,fp16
存储后误差约有 0.004;对于一个 -50 左右的 log_prob 值,fp16
存储后误差约有 0.016。
- 梯度信号被污染:ratio 本该等于 1.0 的地方不等于
1.0,优化器会收到一个虚假的梯度信号,试图”纠正”一个根本不存在的策略差异(
0.016 / 1.0 = 1.6% 的偏离,不仅虚假而且还很强的梯度信号)。
- clip 边界被隐性偏移:假设截断导致 ratio 系统性偏高 0.016,那实际的
clip 区间就从
[0.8, 1.2] 悄悄变成了
[0.816, 1.216](整体上移了 0.016 / 0.2 =
8%)——上下界的不对称会让策略更新方向产生未在预期内的偏好。
- 在长序列场景下被放大:token 级别的 log_prob
累积误差会随序列长度增长。
#### RLHF中的PPO
https://huggingface.co/blog/zh/the_n_implementation_details_of_rlhf_with_ppo
https://zhuanlan.zhihu.com/p/645225982
GRPO(Group Relative
Policy Optimization)
尝试了另一条奖励机制设计的路径:
长期奖励:
GRPO的优势值不再用GAE的方式,而是将整个回合的路径全部生成后计算,不再需要计算某个状态下的后续累积回报的期望ValueModel(state):
\[
\begin{align}
A_{ep_i,token} &= \frac{r_{ep_i} -
\text{mean}(r)}{\text{std}(r)} \\
优势值 &= 该回合的reward距离所有回合的均值有多少个标准差
\end{align}
\]
这种奖励机制设计是在降低奖励预估的难度,从而将更多的算力放在Actor上。ValueModel(state)定位是在所有可能的状态&动作空间上预估的基线(后续累积回报的均值),需要逐action地精准训练;而GRPO是用RewardModel(RewardModel会有listwise的损失函数),对慢模型多次生成的策略路径来打分估算出来的基线,只需要对整个回合的路径打分准确即可。
GRPO-Zero更甚至将RewardModel也去掉,直接用程序/逻辑计算得到其生成结果的reward,即RLVR(verifiable
rule);其优点是不容易出现reward
hacking问题,但泛化性就会下降,在某些场景(数学推理、编程等)会比较好用。
本质上,PPO的基线是在全样本空间上的回报均值,GRPO的基线是在指定的状态下PolicyModel预估概率偏高的策略空间上的回报均值。对于慢模型采样训练的pipeline,只要能保证策略熵不坍缩,GRPO的基线效率会更高,两个原因,一个是因为它隐含了PolicyModel内部的参数信息(类似于ratio的效果),另一个是因为这种基线的预估任务更简单方差更小。但从根本上来说,PPO的潜力应该比GRPO高,不考虑数据稀疏与算力的情况下,PPO的效果应该会更好。
即时奖励:
除了基于长期奖励(又称结果奖励,outcome
reward)的优势函数,还加了基于即时奖励(又称过程奖励,process
reward)的优势函数(相应地也需要提前训好一个预估即时奖励的RewardModel,实现verify
step by step):
\[
A_{ep_i,token_j} = \frac{r_{ep_i,token_j} -
\text{mean}(r)}{\text{std}(r)}
\]
其它细节:
为什么采样时还需要用慢模型采样:因为采样的数据分布直接影响了A的数据分布,如果直接用快模型采样,会导致A的数据分布频繁变化,方差过大,难以收敛。
KL散度损失作为一项直接加到了loss上,避免Actor进行奖励攻击(reward
hacking)或利用奖励信号中某些与原始模型不兼容的特性,从而保证不丢失撰写连贯语句和遵循指令的能力。
通过LLM在MATH任务上Maj@K和Pass@K指标的对比发现:如果RewardModel不能有效泛化到分布外数据,强化学习将仅能稳定Actor的输出分布,
而非提升其核心能力;更甚至说强化学习将只是在扮演一个数据增强的角色。(这个是限制在基于慢模型采样训练的流程,如果不是,结论可能是另一番样子)
DAPO(Decoupled
Clip and Dynamic sAmpling Policy Optimization)
Clip‐Higher:
- 熵坍缩(entropy
collapse)现象:慢模型的采样路径几乎趋于一致,导致策略过早确定性化,探索受限,阻碍模型优化。
- 对于都是优势值大于0的样本:如果是本身概率偏高的(如p_old=0.9)动作,快模型的训练并不会受到clip上限(如p_old
*
(1+0.2)=1.08)的影响,因为概率值最大是1;如果是本身概率偏低的(如p_old=0.01)动作,快模型的训练会被clip上限(如p_old
*
(1+0.2)=0.012)严重影响;即使不考虑概率值上限为1的情况,其允许增加的绝对值也差距很大(原概率偏高的可向上波动量为0.18,原概率偏高的可向上波动量为0.002)。所以当clip上限设置偏低时,便是间接地限制了模型的探索(相对慢模型来说),不利于模型收敛到更优的点。(这个是限制在基于慢模型采样训练的流程,如果不是,结论可能是另一番样子)
动态采样:
- 慢模型采样时只采样所有回合reward不都相同的样本,否则:如果reward都相同,这批样本的优势值将为0;如果优势值为0的样本变多(即策略梯度为零的占比变多),将导致梯度方差增大并削弱模型训练的梯度信号,这会降低样本效率,模型收敛难度也会变大。
即时奖励:
- 只用长期奖励的问题:
- 原始GRPO是将各个回合的loss值各自去做完平均后再加到整体loss上的,这会抑制更长路径的生成,除非其优势值相对较短路径高得多,因为路径越长,均摊到每个动作上的梯度值越小;而如果不用这种平均方式,将会使得第二个问题更严重;
- 因为长期奖励是均摊到每个动作上的,而过长路径常包含无意义内容或重复词语等低质量模式,类似于word2vec不做降采样,这些低质量的高频词语会被过度强化从而导致动作熵值和路径长度出现不合理增长;
- 总之,只用长期奖励的根本性问题是无法有效惩罚长路径中的不良模式。
- 不再用按回合各自平均,而是按query维度整体平均,并将优势值换用即时奖励计算。其实这里只改了损失聚合粒度,并没有从根本上解决问题,能够生成复杂推理的长回合,但会出现路径长度不合理增长的问题,GFPO尝试从样本采样阶段解决该问题。
过长奖励整形:
- 过滤掉因长度过长而被截断的样本,并在reward中增加软性超长惩罚(NLP任务特有的问题)
litePPO
在大模型、小模型、预训练模型、指令微调模型上做的各种已知技巧的消融实验(只在数学推理数据集上做的,适配其它场景时需具体情况具体分析,其价值更大的是其分析思路(即对梯度组成的各部分做枚举分析,看其数值分布与变化走势,并尝试通过case-by-case地做归纳总结),而非结论):
- 基线设计、裁剪策略、标准化策略、过滤策略、损失聚合粒度、附加损失函数、奖励设计。
最终归纳最有用的两个技巧:
- 优势标准化策略:组级均值计算+批次级标准差计算;
- 损失聚合粒度:token级聚合损失;
GSPO(Group Sequence
Policy Optimization)
延续GRPO的思路,不仅对优势值做标准化,对ratio也做标准化,进一步提高训练效率和稳定性。
ratio不做标准化存在的问题:
- 对于负优势的回合,慢模型采样到的某个动作如果概率很低(比如0.001,而快模型即使是一个不高的概率,如0.1,ratio值也很大,且不会被裁剪),会导致高方差训练噪声;(另一个思路是,动作级别的ratio去对回合级别的A做分布矫正,势必会引进更高的方差噪声)
- 并通过截断机制进一步放大(截断比例变高时相当于放大了噪声样本占比),最终导致模型训练效率降低,甚至难以收敛。
- 将ratio改为回合级的,以实现ratio的标准化,降低高方差训练噪声出现的可能(clip的比例虽然从0.13%提升到了15%,但收敛速度&最终效果都比GRPO好):
\[
\begin{align}
ratio_{回合} &= \exp (\frac{1}{回合长度}\sum_{动作}^{回合}{\log
(ratio_{动作})}) \\
&= \prod_{动作}^{回合} \sqrt[回合长度]{ratio_{动作}}
\end{align}
\]
实际实现为(保证只回传到单个动作对应的梯度流上): \[
ratio_{实际实现} = \text{SG}(ratio_{回合})
\frac{p_{actionx}}{\text{SG}(p_{actionx})}
\]
TODO:从异步梯度更新的角度来考虑截断机制的价值吗?或者说慢模型采样并通过加权优势函数训练的本质是异步梯度更新吗?待细索
GFPO(Group Filtered
Policy Optimization)
困难样本挖掘的优化思路。
针对reward相同但长度不同的回合,因为NLP任务的性质,回合长度更长的样本对模型来说更容易学到,但从推理效率、计算成本上来说回合更短的生成结果是我们更想要的,故在慢模型采样阶段引入动作效率之类的metic做困难样本挖掘,一个是进一步提高了训练效率,另一个是通过样本挖掘的metic函数实现了更弱一些的偏好对齐。metic可选有:
- 回合长度的倒数;
- 动作效率:回合reward /
回合长度,允许在奖励比例合理的情况下生成较长路径;
- 事实性、多样性或外部质量分数;
自适应难度(有点focal
loss的意思):通过采样到的所有回合的平均奖励作为该问题的难度(难度的阈值随模型训练动态更新),难度低的只喂给模型少量样本,难度高的喂给模型更多样本。
Expert Iteration
TBD
一些视角
熵机制
softmax模型的RL梯度
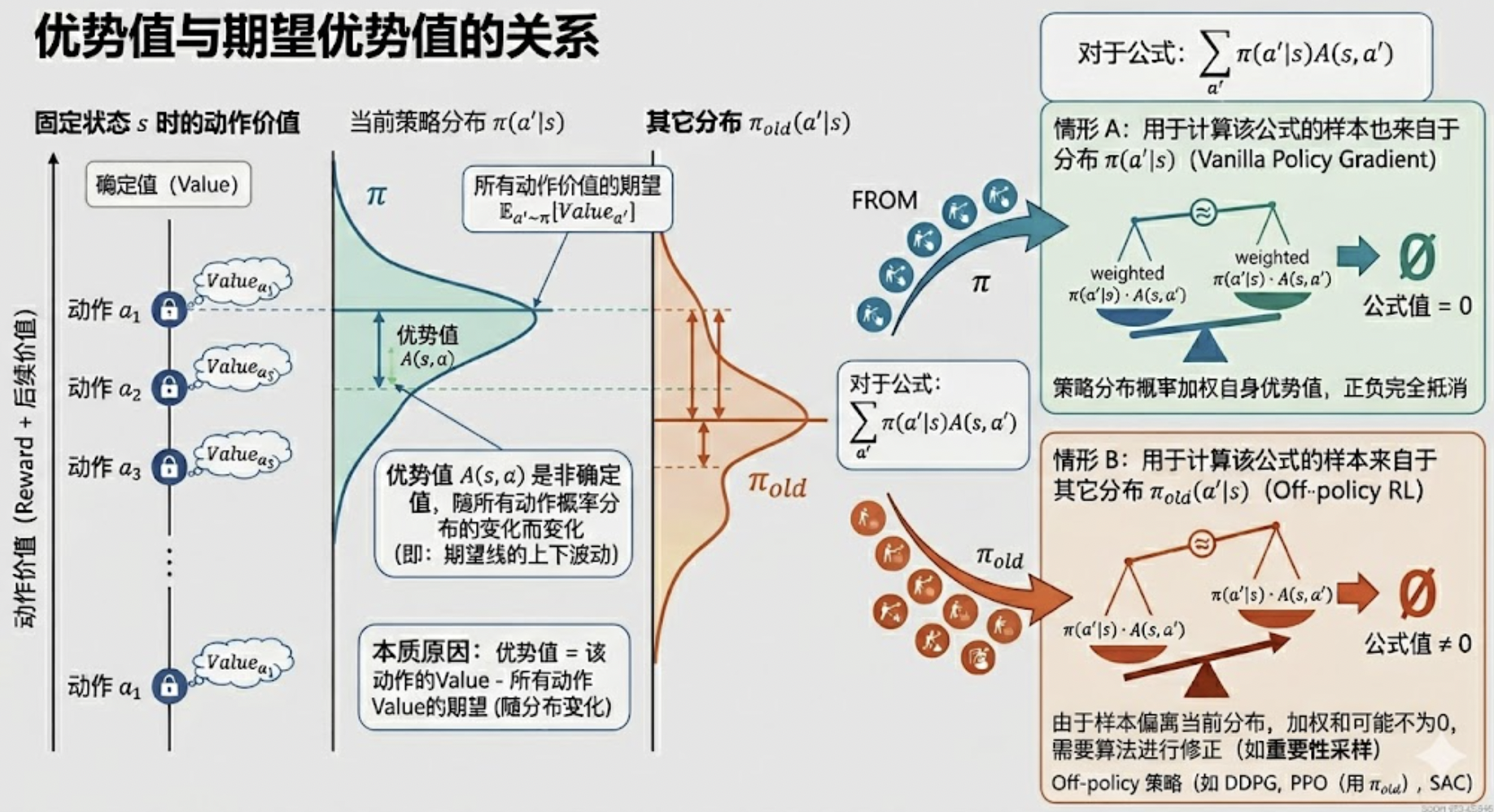
这里关心的是在一次更新前后动作a对应的logit增加或者减少的量,分如下两种情况。
1、Vanilla Policy
Gradient(即采样的和训练的actor是同一个版本的模型,没有重要性采样,损失函数是XXX)下,一次更新后动作a对应的logit变化量如下:
\[
\begin{align}
\Delta logit_a &= z_{s,a}^{k+1} - z_{s,a}^k \\
&= \eta \cdot \frac{\partial
loss}{\partial z_{s,a}} \\
&= \eta \cdot \mathbb{E}_{a' \sim
\pi} \left[ \frac{\partial \pi(a'|s)}{\partial z_{s,a}} A(s,a')
\right] \\
&= \eta \cdot \sum_{a' \sim \pi}
\left[ \pi(a'|s) \cdot \frac{\partial \pi(a'|s)}{\partial
z_{s,a}} A(s,a') \right] \\
&= \eta \cdot \frac{1}{N} \cdot
\sum_{a' \sim \pi} \left[ \frac{\partial \pi(a'|s)}{\partial
z_{s,a}} A(s,a') \right] \\
&= \eta \cdot \frac{1}{N} \cdot \left(
\underbrace{\pi(a|s) \cdot [1 - \pi(a|s)] \cdot A(s,a)}_{a'=a \text{
的项}} + \sum_{a' \neq a} \underbrace{\pi(a'|s) \cdot
[-\pi(a|s)] \cdot A(s,a')}_{a' \neq a \text{ 的项}} \right) \\
&= \eta \cdot \frac{1}{N} \cdot
\pi(a|s) \left( A(s,a) - \sum_{a'} \pi(a'|s) A(s,a') \right)
\\
&= \eta \cdot \frac{1}{N} \cdot
\pi(a|s) \cdot A(s,a) \\
其中:& \\
& \bullet
a是指在状态s下动作a的预估,a'是指在状态s下任意样本(任意动作a')的预估,所以这里在算梯度时不是只看一条样本,而是从所有样本的角度去看的;
\\
& \bullet 若 \pi 是 \text{softmax} 模型,则 \pi(x) =
\text{softmax}(x) 函数的导数是 \frac{\partial \pi(x_{a'})}{\partial
x_a} = \bigl\{^{\pi(x_{a'})\bigl(1-\pi(x_{a'})\bigr), \
a'=a}_{-\pi(x_{a'})\pi(x_a), \ a'\ne
a},其中a是指要看的类别,a'是指样本对应的真实类别; \\
& \bullet
若样本分布与模型预估分布同分布,当固定状态s时,优势函数在随机动作下的期望是0,所以
\sum_{a'} \pi(a'|s) A(s,a') = 0;
\end{align}
\]
2、Off-policy(即采样的和训练的actor是不同版本的模型,
\(ratio=\frac{\pi(a'|s)}{\pi_{old}(a'|s)}\)
,损失函数是XXX)下,一次更新后动作a对应的logit变化量如下: $$ \[\begin{align}
\Delta logit_a &= z_{s,a}^{k+1} - z_{s,a}^k \\
&= \eta \cdot \frac{\partial
loss}{\partial z_{s,a}} \\
&= \eta \cdot \mathbb{E}_{a' \sim
\pi_{old}} \left[ \frac{\partial \left(
\frac{\pi(a'|s)}{\pi_{old}(a'|s)} \right) }{\partial z_{s,a}}
A(s,a') \right] \\
&= \eta \cdot \sum_{a' \sim
\pi_{old}} \left[ \pi_{old}(a'|s) \cdot \frac{\partial \left(
\frac{\pi(a'|s)}{\pi_{old}(a'|s)} \right) }{\partial z_{s,a}}
A(s,a') \right] \\
&= \eta \cdot \sum_{a' \sim
\pi_{old}} \left[\frac{\partial \pi(a'|s) }{\partial z_{s,a}}
A(s,a') \right] \\
&= \eta \cdot \left(
\underbrace{\pi(a|s) \cdot [1 - \pi(a|s)] \cdot A(s,a)}_{a'=a \text{
的项}} + \sum_{a' \neq a} \underbrace{\pi(a'|s) \cdot
[-\pi(a|s)] \cdot A(s,a')}_{a' \neq a \text{ 的项}} \right) \\
&= \eta \cdot \pi(a|s) \left( A(s,a) -
\sum_{a' \sim \pi_{old}} \pi(a'|s) A(s,a') \right) \\
其中:& \\
& \bullet
a是指在状态s下动作a的预估,a'是指在状态s下任意样本(任意动作a')的预估,所以这里在算梯度时不是只看一条样本,而是从所有样本的角度去看的;
\\
& \bullet 因为样本来自旧模型,即 A 与正在训练的模型预估分布 \pi
不是同分布,故当固定状态s时,优势函数在新策略分布下的期望不是0,即
\sum_{a'} \pi(a'|s) A(s,a') \ne 0;
\end{align}\] $$
从梯度更新的角度来看ratio的作用机制:
- 与不做相比,会在导数中优势值的那一项上减去一个常数(与当前动作无关,只与当前策略分布和历史策略分布有关的一个常数项,即
\(\bar{A}(s) = \sum_{a' \sim \pi_{old}}
\pi(a'|s) A(s,a')\)
),将动作的优势值变成一个不仅是相对其它动作的优势值,也是相对当前策略已经优化到的位置的优势值。
- 该常数项的本质是当前新策略 \(\pi\)
在状态 \(s\)
下,以旧策略采样的样本分布为度量标准算出的“当前新策略的优势值期望”(即对于当前新策略倾向于选择的动作,在旧数据里看是不是平均能拿更高的分(旧策略的平均应当是0))。它的价值在于为模型提供了一个“当前策略已经优化到的水平(Dynamic
Centering
Baseline)”,正负样本不再是固定不变的,而是随着训练动态变化的,即即使某个动作在过去算是个好棋(优势值
\(A>0\)),但只要它达不到新策略目前的平均水平(\(A < \bar{A}(s)\)),其 Logit
就会被无情打压。这与focal
loss不同,并非仅仅调整样本权重大小,而是会随着训练反转正负样本。最终导致策略熵塌缩、促使模型向唯一完美思维链拟合。
- 当然在实际工程中完全依赖该常数项会有问题(ratio方差爆炸),因为实际训练过程中该常数项只是用小批量样本近似估计的,必然会有统计噪声,如果新策略偏离旧策略太远(比如旧策略几乎不采样的冷门动作),少量的噪声在巨大的ratio下被放大,直接训崩;
- 新策略与旧策略容易偏离的原因:
- 这里的偏离指的是ratio,而非模型参数,是指最终输出的概率值的比值,而非模型输出的logit值的大小。概率是拿logit通过softmax得到的,有指数放大效应,logit的线性更新在概率空间中会变成指数级变化,这是softmax模型的性质。
- off-policy的多步更新,加大了偏离的可能。
- 优势值的尖峰扰动(常用grpo、grad_clip等方式规避)。
- 训崩(没训好)的两种情况:
- 状态分布过度漂移(自回归多米诺骨牌效应):新策略是在旧策略的数据分布上训练的,如果新策略偏离旧策略太远,那么在下一个pass时,新策略做rollout的过程中会因为生成了一些没怎么训练过的状态导致出现不可用样本。
- 策略过早塌缩(探索能力永久丧失,类似于梯度弥散):小批量样本的噪声叠加不做偏离限制(巨大ratio)的情况下,基于softmax的指数放大效应,非常容易把某个概率直接推到
0.9999,其他动作压到接近
0,而梯度更新的公式中含有动作概率这一项,所以概率触底的动作很难再拉回来了。
softmax模型的策略熵
策略熵快速下降的机理
基座模型决定论:
- RL只是将训练样本空间中的点塞得更密集一些,从而完成对某些路径的过拟合(如deepseekR1、Echo
Chamber、Limit of RLVR)
- 仅对高熵token进行策略梯度更新可以显著提高模型的推理性能(啥叫高熵token?看下论文)
- 仅使用负样本进行训练(NSR)在 Pass@k
的整个范围内都能显著提升模型性能,甚至在某些情况下超过了 PPO 和 GRPO
等常用强化学习算法(Pass@1和Pass@k的tradeoff)
softmax模型的策略熵,在一次更新后,策略熵的变化约等于动作a在更新前的对数概率与更新前后
logits 变化之间的负协方差,即策略熵的变化由“动作概率”和“logit
更新量”之间的协方差驱动: - 当一个动作 a
在更新前从策略中获得了高概率,并且其对应的 logit
在更新后也在增加,那么它将降低策略熵,降低部分的量级约等于协方差的量级:
\(\Delta H \approx -\text{Cov}_{\pi}(\log
\pi(a), \Delta logit_a)\) 。 - 协方差 \[\text{Cov}(X, Y) = E[(X - E[X])(Y -
E[Y])]\] ,衡量更新力(Update)是否在顺着模型本来的意图(Current
Policy)使劲。 - 其中\(X = \log
\pi(a)\),更新前的对数概率,代表了更新前的模型对动作
\(a\) 的偏好,\(X - E[X]\) 衡量模型对动作 \(a\) 的偏好是否比“平均水平”更高; - 其中
\(Y = \Delta
logit_a\),更新前后的 logit 变化量,即 RL
算法给出的奖励信号,\(Y - E[Y]\)
衡量对动作 \(a\)
的更新是否比“平均推力”更强; -
协方差是两者的乘积,可以看作是模型既有偏好与外界奖励信号之间的“共鸣度”;
- \(\Delta logit_a = \eta \cdot \pi(a|s)
\left( A(s,a) - \sum_{a' \sim \pi_{rollout}} \pi(a'|s)
A(s,a') \right)\)
(证明过程如上小节),即一次更新后该动作a对应的logit增加或者减少的量,即更新力。
-
一般『高协方差』说明模型的信心和正确性对齐了;通过RL把模型已有的正确倾向变得更确定,通过熵快速下降,把已有的高置信正确轨迹进一步蒸馏进策略里,从而使得RL后的效果比SFT更好。(前提是这个正确性是真的全局正确,如果是局部正确就会导致模型探索不足、过早收敛)
在训练过程中控制策略熵的方法
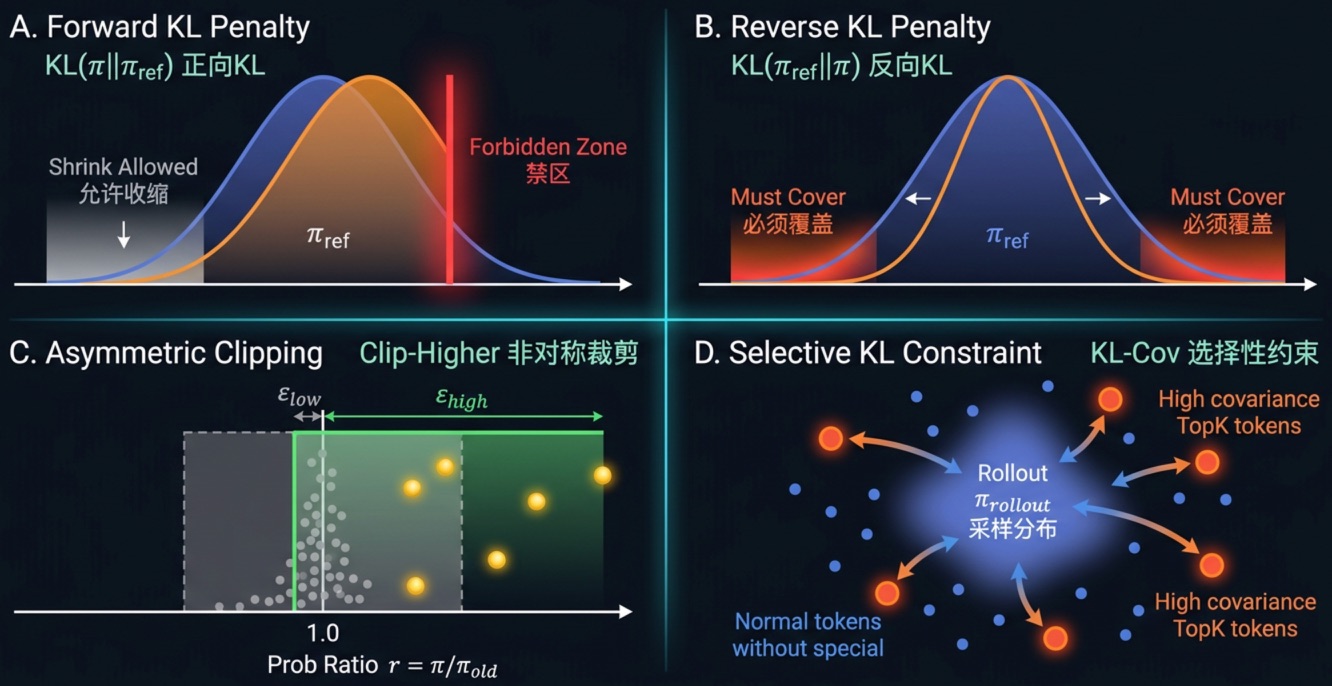
注意,这些额外增加的损失项,
1、loss中直接增加熵损失:
\(L=L_{GRPO}+(-\beta \text{H}),\
\text{H}=-\sum_{batch}\pi(a|s)\log\pi(a|s)\)
直接奖励高熵,简单但全局生效,容易扰乱低熵语法/格式token,系数也敏感
2、增加策略模型和参考模型之间的 KL 惩罚:
- \(L=L_{GRPO}+\beta
D_{KL}(\pi\|\pi_{ref}),\ D_{KL}(\pi\|\pi_{ref}) =
\text{CE}(\pi,\pi_{ref}) - \text{H}(\pi) = (-\sum_{batch} \pi \log
\pi_{ref}) - (-\sum_{batch} \pi \log \pi)\)
- 能稳住基线(比如LLM中的语言能力,Rec中的兴趣匹配能力)、防止奖励攻击;但过强会压制新能力的探索(比如数学推理中的长CoT,推荐排序中的相互作用后的LTV/茧房突破等)
- 因为训练样本的分布比较接近 \(\pi\)
,所以实操时的简化计算有如下两种:
- \(D_{KL}(\pi\|\pi_{ref}) =
\frac{1}{N}((-\sum_{batch} \text{sg}(\log \pi_{ref})) - (-\sum_{batch}
\log \pi)) = \frac{1}{N} \sum_{batch}(\log \pi - \text{sg}(\log
\pi_{ref}))\)
- 该计算方式,是单点采样上的无偏估计,更适合当监控指标,而非loss,因为在自动求导器下作为加和项的
\(\text{sg}(\log \pi_{ref})\)
这部分会消失,若作为loss,将会变成无视任何条件地最小化参考模型采样到的所有样本
- \(D_{KL}(\pi\|\pi_{ref}) = \frac{1}{N}
\sum_{batch}(\log \pi \cdot \text{sg}(\log \pi - \log
\pi_{ref}))\)
- 该计算方式,源于梯度计算公式的反推,即保证梯度结果一致即可的工程实现方案:
\(\begin{align} \nabla D_{KL}(\pi\|\pi_{ref})
&= \nabla \mathbb{E}_{\pi}(\text{sg}(\log \pi - \log \pi_{ref})) \\
&= \sum_{batch} (\nabla (\pi \cdot \text{sg}(\log \pi - \log
\pi_{ref})) \\ &= \sum_{batch} (\pi \cdot \nabla \log \pi \cdot
\text{sg}(\log \pi - \log \pi_{ref})) \\ &= \mathbb{E}_{\pi}(\nabla
\log \pi \cdot \text{sg}(\log \pi - \log \pi_{ref}))
\end{align}\)
- 之所以不是 \(\frac{1}{N} \sum_{batch}(\log
\pi \cdot (\log \pi - \text{sg}(\log \pi_{ref})))\)
,是为了避免策略模型参数上的梯度既影响“你抽到哪个词”,又影响“这个词的惩罚有多大”,两者相互耦合,这容易导致模型为了降低
loss
而去钻数学漏洞(比如将参考模型估得高的部分估得更高,让分布变得极度尖锐)
- 一般习惯上常写成 \(D_{KL}(\pi\|\pi_{ref})
= - \frac{1}{N} \sum_{batch}(\log \pi \cdot \text{sg}(\log \pi_{ref} -
\log \pi))\)
- \(D_{KL}(\pi\|\pi_{ref})\)
:衡量用参考模型去编码策略模型的分布时,相较完美编码(策略模型)占用信息量增加的量
- KL的方向是策略模型挑样本、参考模型做审判,所以该正则项优化的方向是惩罚那些
策略模型输出概率高但参考模型输出概率低
的样本(因为这些是容易被挑到&loss偏高的样本),通过降低该正则项的值,最终效果是
允许策略模型减少参考模型原本会采样的动作、但不允许策略模型跑到参考模型很少涉及的区域;
- \(D_{KL}(\pi_{ref}\|\pi)\)
:衡量用策略模型去编码参考模型的分布时,相较完美编码(参考模型)占用信息量增加的量
- KL的方向是参考模型挑样本、策略模型做审判,所以该正则项优化的方向是惩罚那些
参考模型输出概率高但策略模型输出概率低
的样本(同样因为这些是容易被挑到&loss偏高的样本),通过降低该正则项的值,最终效果是
不允许策略模型减少参考模型原本会采样的动作;
3、增加策略模型和rollout模型之间的 KL 惩罚:
- \(L=L_{GRPO}+\beta
D_{KL}(\pi_{rollout}\|\pi),\ D_{KL}(\pi_{rollout}\|\pi) =
\text{CE}(\pi_{rollout},\pi) - \text{H}(\pi_{rollout}) = (-\sum_{batch}
\pi_{rollout} \log \pi) - (-\sum_{batch} \pi_{rollout} \log
\pi_{rollout})\)
- 因为训练样本的分布就是 \(\pi_{rollout}\) ,所以实操时可简化为:
\(D_{KL}(\pi_{rollout}\|\pi) =
\frac{1}{N}((-\sum_{batch} \log \pi) - (-\sum_{batch} \log
\pi_{rollout}))\)
- 与2类似,但KL方向相反,最终效果是
不允许策略模型减少参考模型原本会采样的动作,从而限制策略模型相对rollout模型的单轮偏移,降低状态漂移;但过强会压制对正确路径的强化,导致模型收敛不足;
4、通过Clip-Higher策略强化旧策略下低概率高优势的动作:
- \(\epsilon_{high}>\epsilon_{low},\
\text{clip}(r_t,1-\epsilon_{low},1+\epsilon_{high}),\
r_t=\frac{\pi(a_t|s_t)}{\pi_{old}(a_t|s_t)}\)
- 放宽正优势上裁剪,让探索token有更大增幅;但会放大奖励噪声;
5、通过Clip-Cov策略随机屏蔽掉部分样本,控制高协方差token的更新量:
- \(L=\mathbf{1}_{t\notin
I_{clip}}L_{GRPO},\ I_{clip}\sim Rand(\{t:c_l<c_t<c_u\},\rho),\
c_t=(\log\pi_t-\overline{\log\pi})(A_t-\bar A)\)
- 直击熵坍缩来源,高效控制策略熵;但阈值/比例过强会丢有效强化信号;
6、通过KL-Cov策略对部分样本额外增加策略模型和rollout模型之间的 KL
惩罚,控制高协方差token的更新量:
- \(L=L_{GRPO}+\beta\mathbf{1}_{t\in
I_{kl}}D_{KL}(\pi_{rollout}\|\pi),\ I_{kl}=TopK(c_t,\rho)\)
- 比Clip-Cov更平滑,不会直接丢弃,而是利用rollout模型将其拉回一点;但过强会变成保守更新,影响收敛速度;
7、增加熵基优势函数项(优势整形),调整不同动作的更新强度:
- \(A' = A + \psi(\mathcal{H}_t(s)),\
\psi(\mathcal{H}_t(s)) = \min \left( \alpha \cdot
\mathcal{H}_t^{\text{detach}}(s), \frac{|\boldsymbol{A}|}{\kappa}
\right)\)
- 熵基优势函数项通过min做截断,一是防止发生正负样本反转的情况,二是避免过度奖励;
- 各种情况罗列:
- 若发生了截断,则正样本 \(A'=(1+\frac{1}{\kappa})A\) 、负样本
\(A'=(1-\frac{1}{\kappa})A\)
,通过截断避免过度奖励或样本反转;会导致截断的两种情况:
- 策略熵过大,即模型在该位置上非常不确定:
- 刚开始训练,优势值主要来自随机采样差异,截断后只做有限探索加权,避免把随机高熵误当成稳定信号;
- A>0但偏小,截断后 \(A'=(1+\frac{1}{\kappa})A\)
,适度强化但不让弱正样本变成强监督信号;
- A>0但偏大,截断后 \(A'=(1+\frac{1}{\kappa})A\)
,模型探索到了一条创新路径,因A本身偏大,相当于在大力强化该新发现的高价值动作,相对于优势值同样大小、但熵偏低的动作,模型会更强化该熵偏高的新动作;当然相对于优势值更大、但熵偏低的动作,就看超参怎么调,来平衡两者的取舍了;
- A<0但偏小,截断后 \(A'=(1-\frac{1}{\kappa})A<0\)
,减弱对高熵探索动作的惩罚,但不让负样本反转为正样本;相对于优势值同样大小、但熵偏低的动作,模型对该熵偏高的新动作惩罚力度会更小些,即整形后的优势值会往0这边回拉得更多一些;
- A<0但偏大,截断后 \(A'=(1-\frac{1}{\kappa})A\)
,仍然惩罚明显低质动作,只是避免在高不确定位置上过度压制探索;
- 优势值过小 &
模型在该位置上熵还没有收敛得很低,模型在该状态下尚未探索到比较好的路径,因
\(\frac{|A|}{\kappa}\)
很小而触发截断,使该样本近似低权重更新,避免从高熵里制造伪优势;
- 若未发生截断,则 \(\psi=\alpha\mathcal{H}_t^{\text{detach}}(s)\)
,高熵token获得更大的优势修正、低熵token基本不变;detach保证熵项只重加权策略梯度,不直接反传去优化熵本身;
- 总之,无论截断与否,都是高熵token在正优势上更新步伐更大些,在负优势上更新步伐更小些;通过用
\(\mathcal{H}_t^{\text{detach}}\)
做优势整形,把更多预算分给尚不确定的位置。优点是比全局熵损失更定向,能强化高熵高价值动作
&
减轻对高熵负样本的过早打压;缺点是会系统性偏向高熵token,若reward/优势值噪声较大,可能放大偶然正样本或拖慢低质高熵动作的收敛,比较依赖
\(\alpha,\kappa\) 的调参。
一些评价指标
pass@K:让模型生成 K 次,只要其中至少 1 个正确,就算预估正确(K
次尝试里有没有对的,衡量模型能力上限)
maj@K:让模型生成 K
次,出现次数最多的结果是否正确(衡量分布是否稳定)
HR@K:让模型生成 1 次,topK个结果中只要其中至少 1
个正确,就算预估正确(前 K 个结果里是否有正确的)
recall@K:让模型生成 1 次,topK个结果中正确个数 /
ground-truth个数(前 K
个结果里找到了多少,衡量模型召回能力;当GT只有一个时等价于HR@K)
PPL:计算公式为 \((\prod_{i}\frac{1}{p_i})^{1/N}\)
或者考虑数值稳定用 \(exp(\text{NNL}_{avg})\)
,N为当前生成的token长度。体现模型预估成ground-truth时的困惑度,其值的直观含义为模型如果要选到GT
平均上会在 PPL
个候选上纠结(衡量模型分布对GT分布的拟合程度,类似KL散度的作用)
策略熵:即每个生成位置上的平均不确定性, \(H = -\frac{1}{N_{token}}\sum_{batch} \sum_{sample}
H_t(s) = -\frac{1}{N_{token}}\sum_{batch} \sum_{sample} \sum_{a \sim
Vocab}\pi(a|s)\log\pi(a|s)\)
常见问题
值函数收敛问题
致命三角(deadly triad):https://zhuanlan.zhihu.com/p/2883455468