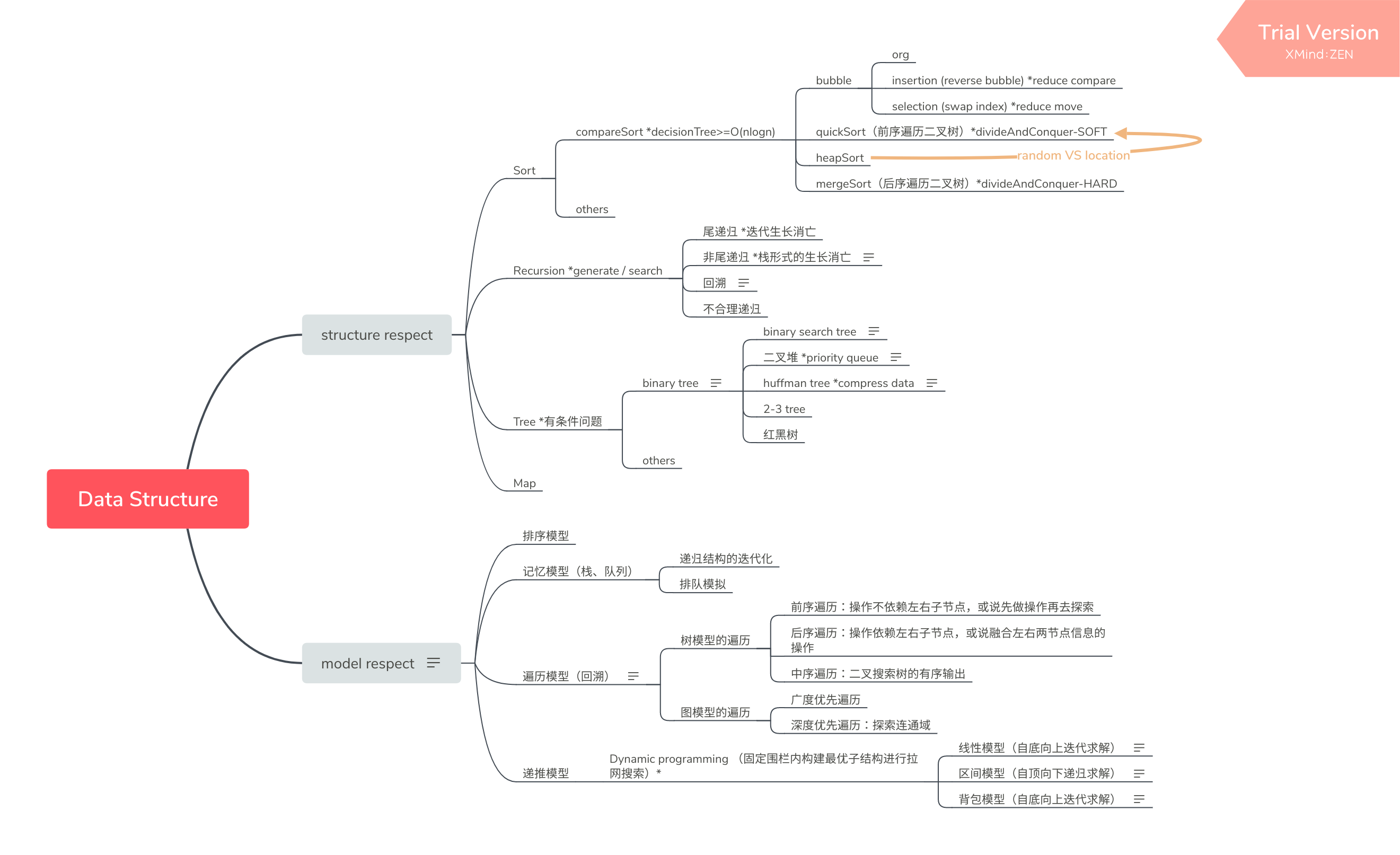
数据结构的选择:首先得有一堆数据,然后,在确定了这堆数据所需的抽象操作后,便可依据这些抽象操作及运行环境来进一步决定“哪种数据结构的实现形式最有效“。
时间复杂度是用来描述随着问题规模的扩大,程序运行时间会有如何的增长速度。这也是\(\mathcal{O}(2n) = \mathcal{O}(n)\)的原因。
称\(\mathcal{O}(1),\mathcal{O}(\log n), \mathcal{O}(n), \mathcal{O}(n^c)\)为多项式级的复杂度,称\(\mathcal{O}(c^n), \mathcal{O}(n!)\)为非多项式级的复杂度。
为使不同算法之间的比较独立于机器,定义排序算法的两个关键属性——比较次数和移动次数,并用大\(\mathcal{O}\) 近似给出,表示这些次数的数量级。

template <class T>
void bubbleSort(T data[], int size) {
for (int top=0, b; top<size-1; ++top) {
for (b=size-1; b>top; --b) {
if (data[b]<data[b-1])
swap(data[b], data[b-1]);
}
}
}该算法无视数据的原始顺序,任何情况下,比较次数和移动次数均为 \(\mathcal{O}(n^2)\) 。
可看做冒泡的进阶,通过交换索引的方式,降低了移动次数。
template <class T>
void selectionSort(T data[], int size) {
for (int i=0, j, least; i<size-1; ++i) {
for (least=i, j=i+1; j<size; ++j) {
if (data[j] < data[least])
least = j;
}
if (least != i)
swap(data[least], data[i]);
}
}该算法无视数据的原始顺序,任何情况下,比较次数均为 \(\mathcal{O}(n^2)\) ,移动次数均为 \(\mathcal{O}(n)\) 。
可看做反向冒泡,相较前两种,更充分地利用了数据的现有情况。

template <class T>
void insertionSort(T data[], int size) {
for(int r=1, l; r<size; ++r) {
T tmp = data[r];
for(l=r-1; l>=0 && data[l]>tmp; --l)
data[l+1] = data[l]; //腾出位置以便插入
data[l+1] = tmp;
}
}缺点:
优点:
最好的情况下,比较次数和移动次数均为 \(\mathcal{O} (n)\) ;最坏的情况下,比较次数和移动次数均为 \(\mathcal{O} (n^2)\) ;平均情况下,比较次数和移动次数均为 \(\mathcal{O} (n^2)\) 。
在平均情况下,冒泡排序的比较次数近似为插入排序的两倍,移动次数与插入排序相同;而冒泡排序与选择排序的比较次数是一样的,移动次数比选择排序多 n 次。
当数据具有比较良好的结构时(即一些大的元素在数组底部,小的元素在数组顶部),可对冒泡排序添加一个标志位,当某次冒泡过程中没有发生交换时,就可以终止排序。
由此有了梳排序:按不同步长进行比较交换实现对数据的预处理,最后进行有标志位的冒泡排序。
template <class T>
void combSort(T data[], int size)
{
int step = size;
while((step=(int)(step/1.3)) > 1)
for(int b=size-1; b>=step; --b) {
if(data[b] < data[b-step])
swap(data[b], data[b-step]);
}
bool done = false;
for (int top=0, b; top<size-1 && !done; ++top) {
done = true;
for (b=size-1; b>top; --b)
if (data[b]<data[b-1]) {
swap(data[b], data[b-1]);
done = false;
}
}
}梳排序中预处理阶段的比较次数约为 \(\mathcal{O}(n \lg n)\) ,无视数据顺序。
所有的基于比较的排序算法均可写为决策树的形式,故通过对决策树的分析可以得到对基于比较的排序算法更为深入的理解。
i 层完全决策树有 \(2^{i-1}\) 个叶子节点, \(2^{i-1}-1\) 个非叶子节点,故对于更为一般的 i 层决策树的叶子节点数 m 和非叶子节点数 k 满足: \(m\le 2^{i-1}, k\le 2^{i-1}-1\) 。
n 个元素的数组有 n! 种排列情况,每种排列情况都可通过一个叶子节点来表示,但排序算法会出现重复和无效的情况,故决策树还会出现一些额外的叶子节点,因此 \(n!\le 2^{i-1}\) ,即完全决策树的叶子节点数是数组排列情况数的上限。
排序算法在最坏情况下的时间复杂度即为相应决策树的深度 i ,又由上一条的结论可得: \(i-1\le \lg(n!) \le \mathcal{O}(n\lg n)\) ,故基于比较的排序算法可达到的最好的时间复杂度为 \(\mathcal{O}(n \lg n)\) 。
遵循将原始问题变为能更容易、更快速解决的子问题这一原则,在排序的准备过程中实现对数据的排序,这个准备过程即为找到边界值并划分为两个子数组的递归过程。
在这个准备排序的过程中,排序的思想有些模糊,而这个过程却正是快速排序的核心所在。
采用对边界值选择的不同策略,以及对两个子数组的不同划分方式,可产生快排的各种不同的分支,按对两个子数组的不同划分方式可粗略的分为两类:
void quicksort(int s[], int l, int r)
{
if(l < r) {
int i = l, x = s[l], j = r;
while(i < j)
{
while(i<j && x<s[j]) // find greater
--j;
if(i<j) // 莫忘该条件!
s[i++] = s[j];
while(i<j && s[i]<x) // find less
++i;
if(i<j)
s[j--] = s[i];
}
s[i] = x; // have found the bounder postion
quicksort(s, l, i-1);
quicksort(s, i+1, r);
}
}template <class T>
void quickSort(T data[], int l, int r)
{
int l1 = l, r1 = l, l2 = r, r2 = r;
// choose the middle element to be the bound
swap(data[l], data[(l+r)/2]);
T bound_data = data[l];
int bound_idx = l;
++r1;
while(r1 <= l2) { // "=" for 2 entries subarray
while(data[r1] <= bound_data)
++r1;
while(bound_data < data[l2])
--l2;
if(r1 < l2)
swap(data[r1], data[l2]);
}
--r1, ++l2;
swap(data[bound_idx], data[r1]);
--r1;
if(l1 < r1)
quickSort(data, l1, r1);
if(l2 < r2)
quickSort(data, l2, r2);
}
template <class T>
void quickSort(T data[], int size)
{
int i, max;
for(i=1, max=0; i<size-1; ++i) {
if(data[i] > data[max])
max = i;
}
// avoid r1 of the left subarray out of range
swap(data[size-1], data[max]);
quickSort(data, 0, size-2);
}若将原始数组看做一棵树的根节点,那么每次划分便会产生更深一层的叶子节点。但无论边界值在哪划分结果如何,对于同一层的所有叶子节点所需要的比较次数之和均为 \(\mathcal{O}(n)\) ,故该树产生的层数越深,比较复杂度越高,最好的情况为 \(\mathcal{O}(\lg n)\) ,最差的情况为 \(\mathcal{O}(n)\) ,平均情况为 \(\mathcal{O}(\lg n)\) 。
另外,快速排序算法并不适合小型数组,对于小于30个数据项的小数组来说,插入排序比快速排序更有效,故可以子数组长度为条件对算法做融合。
快速排序很难控制划分过程,难以保证划分产生的子数组有大致相同的长度;归并排序不去控制划分过程,而通过添加一新的条件,去着重于合并两个已排好序的数组。
合并过程中我们可以保证如果两个当前元素相等时,我们把处在前面的序列的元素保存在结 果序列的前面,这样就保证了稳定性。
void merge(int *a, int begin, int end, int *tmp)
{
int mid = (begin+end)/2;
int l1=begin, l2=mid, i=begin;
while(l1<mid && l2<end) {
while(l1<mid && a[l1]<a[l2])
tmp[i++] = a[l1++];
while(l2<end && a[l2]<a[l1])
tmp[i++] = a[l2++];
}
while(l1<mid)
tmp[i++] = a[l1++];
while(l2<end)
tmp[i++] = a[l2++];
for(i=begin; i<end; ++i)
a[i] = tmp[i];
}
void mergeSort(int *a, int begin, int end, int *tmp)
{
if(end - begin > 1) {
int mid = (begin+end)/2;
mergeSort(a, begin, mid, tmp);
mergeSort(a, mid, end, tmp);
merge(a, begin, end, tmp);
}
}任何情况下,比较次数和移动次数均为 \(\mathcal{O}(n \lg n)\) 。

用迭代来取代递归或者对短长度的子数组使用插入排序,将提高归并的效率,以迭代为例,示例代码如下:
归并需要额外的 \(\mathcal{O}(n)\) 的存储空间,对于大数据来说这是不现实的,一个解决方法是使用链表,示例代码如下:
依据结构,可将二叉树分为满二叉树、完全二叉树、平衡二叉树和其它。在满二叉树的基础上,在最底层从右往左删除若干节点得到的便是完全二叉树。而平衡二叉树是左右两个子树的高度值相差不超过1的树。
树的度为2的节点个数总比叶子节点个数少1个。若层数从1开始数起,满二叉树第k层的节点个数为\(2^{k-1}\),总节点个数为\(2^k - 1\)。
- 对于用数组来存储数据,用二分法来做查找的情况,会面临插入操作十分复杂的问题
- 对于用链表来存储数据,用断裂重连的方法来做插入的情况,会面临查找操作十分复杂的问题
而二叉查找树这种数据结构融合了二者的优点,解决了二者的缺点,十分适用于数据的查找。
查找算法的复杂度通过查找过程中的比较次数来度量。
构建一棵二叉查找树相当于向一棵空树中插入 n 个节点,其最坏情况下的复杂度为 \(\mathcal{O}(n^2)\) ,最好情况与平均情况均为 \(\mathcal{O}(n \lg n)\) 。
树的遍历可分为广度优先遍历(体现树的结构)与深度优先遍历(体现排序)。
深度优先遍历是尽可能地向同一个方向进行(左或右),
拔高的理解方向 https://www.cnblogs.com/yangecnu/p/Introduce-Red-Black-Tree.html 。
若用链结构,堆的插入操作将十分复杂,又因堆的性质(完全平衡,且最后一层的叶子都处于最左侧的位置(完全二叉树),即堆中每个元素的位置可用一固定的关系式索引),可用数组更为方便的实现。具体为:设数组下标为0的位置为完全二叉树的根节点,记为节点0,因为树的度为2的节点个数总比叶子节点个数少一个,所以节点k的左右子节点分别为节点2k+1和2k+2,父节点为节点\(floor(\frac{k-1}{2})\)。
重建堆的时间复杂度为\(\mathcal{O}(n)\),将堆做排序的时间复杂度为\(\mathcal{O}(n\log n)\),故用堆排序对无序数组做排序的时间复杂度为\(\mathcal{O}(n\log n)\)。
用数组实现最小堆如下:
template<class T, int capacity>
class HeapTree {
public:
HeapTree() { tree.reserve(capacity); }
HeapTree(const T& e) {
tree.reserve(capacity);
tree.push_back(e);
}
~HeapTree() { tree.clear(); }
bool isEmpty(void) const { return tree.empty(); }
void insert(const T& e);
T popRoot(void);
private:
std::vector<T> tree;
void moveDown(int begin, int end);
};
template<class T, int capacity>
void HeapTree<T, capacity>::insert(const T& e)
{
tree.push_back(e);
int i, j;
i = j = tree.size() - 1; // real index
while(i != 0) {
--i /= 2;
if(tree[i] > tree[j]) {
swap(tree[i], tree[j]);
j = i;
}
else break;
}
}
template<class T, int capacity>
T HeapTree<T, capacity>::popRoot(void)
{
T el = tree.front();
swap(tree.front(), tree.back());
tree.pop_back();
moveDown(0, tree.size());
return el;
}
template<class T, int capacity>
void HeapTree<T, capacity>::moveDown(int begin, int end)
{
int i, j = begin;
i = 2*j + 1;
while(i <= end-1) { // 有左子节点
if(i <= end-2 && tree[i] > tree[i+1]) //有右兄弟节点&&右兄弟节点更小
i = 2*j + 2;
if(tree[j] > tree[i]) {
swap(tree[j], tree[i]);
j = i;
i = 2*j + 1;
}
else break;
}
}完全平衡树(AVL树):所有节点的左子树与右子树的高度差均不能超过1;将左子树的高度减去右子树的高度称为该节点的平衡因子(BF)。

记忆序列,在需要遍历操作时可利用记忆特性实现一些特殊需求,如树的遍历、链表反转、符号匹配、大数相加等。
等待序列,可模拟实现排队论中的模型。
四种实现方式
因为大多用堆实现,故可以直接看为堆,另起名为优先队列的原因是为方便思考(在使用时表现为带优先级的队列)。
demo 如下:
void test_proprityQueue(void)
{
HeapTree<int, 10> pq;
int a[] = {1, 1, 0, 4, 5, 3, 3, 3};
for(int i=0; i<8; ++i)
pq.insert(a[i]);
while(!pq.isEmpty())
cout << pq.popRoot() << ", ";
cout << endl;
}系统在实现时利用的是具有记忆特性的栈。
定义新对象或新概念的基本规则之一是:定义中只能包含已经定义过的或含义明显的术语,否则需要给定义加上形式约束,以保证其满足存在性和唯一性。这种打擦边球的定义称为递归定义,主要用于定义无限集合。
递归定义由两部分组成:锚(anchor)和产生新对象的构造规则。
递归常用于两个场景:生成和查找。
使用递归的好处是逻辑上的简单性和可读性,其代价是降低了运行速度(额外的函数调用和不必要的迂回计算)
递归调用不是表面上的函数调用自身,而是一个函数的实例调用另一个函数的实例(这些调用在底层表示为不同的活动记录,并由系统区分,详见blank)。
按应用的任务一般分为以下 5 类。
(单道)正向循环。
void fun1(int i) {
if(i > 0) {
cout << i << ", ";
fun1(i-1);
}
}(叉道)反向循环。
void fun2(int i) {
if(i > 0) {
fun2(i-1);
cout << i << ", ";
}
}将非尾递归形式转化为迭代形式都需要显示地使用栈,如二叉树的深度优先遍历。
尾递归是迭代生长消亡,非尾递归是栈形式的生长消亡。单条的非尾递归是条型的栈,多条的非尾递归是树型的栈(有几句递归调用便是几叉树,与调用是否在同一语句无关)。
多条非尾递归时间复杂度为\(\mathcal{O}(k^h)\) ,其中h为树的深度,k为树的叉数。
计算二叉树叶子节点数的递归程序完美地诠释了递归的针对无限集合的生成和查询功能,如下:
int num = 0;
void calLeafNum(Node *p)
{
if(p) {
if(p->left || p->right) {
calLeafNum(p->left);
calLeafNum(p->right);
}
else
++num;
}
}尝试一条路径不成功后,返回最近的十字路口尝试另一条路径,这种方法称为回溯。使用回溯法可以回到出发位置,这为成功解决问题提供了其他可能性。使用回溯须具备以下两个条件:
求解八皇后问题的实例代码片段如下:
void ChessBoard::putQueen(int row)
{
for(int col=0; col<square; ++col) {
if(column[col] == avaliable &&
left_diagonal[row+col] == avaliable &&
right_diagonal[row-col+norm] == avaliable) {
position_in_row[row] = col;
column[col] = !avaliable;
left_diagonal[row+col] = !avaliable;
right_diagonal[row-col+norm] = !avaliable;
if(row < square-1)
putQueen(row+1);
else
printBoard();
// below opts for backtracking
position_in_row[row] = -1;
column[col] = avaliable;
left_diagonal[row+col] = avaliable;
right_diagonal[row-col+norm] = avaliable;
}
}
}少见
有些任务不适合用递归来解决,如求解斐波那契数列,这种任务若用递归来解决则会出现多次重复同样计算的情况,计算复杂度会呈指数级增长。
递归相当于构建了一棵树,对于不合理递归是指该任务不适合构建成一棵树来解决。
不合理递归常见的代码形式为在同一行代码里出现两次或两次以上的递归调用,如
return fun(i-1) + fun (i-2) 。
哈夫曼编码即为最优前缀编码,通过最优二叉树实现。
它的另一个性质是具有编解码时的无歧义(这也是前缀编码希望具有的性质,否则在编解码时会十分冗杂)。这是因为它采用二叉树的结构进行编码,若要编解码出现歧义,那么某个字符的编码需成为另一个歧义字符的编码的前缀,对应在二叉树上便是目标对象不在叶子节点上,而是在歧义目标对象的编码路径上。哈夫曼编码通过强制规定目标对象必须均在叶子节点上的方法,实现了编解码时的无歧义性。
用优先队列实现如下:
void create_huffman_code(void)
{
float probs[] = {0.09, 0.11, 0.19, 0.22, 0.39}; // E, D, C, B, A
const int len_probs = sizeof(probs) / sizeof(float);
int *codes = new int[2*len_probs - 1];
HeapTree<float, len_probs> pq;
for(int i=0; i<len_probs; ++i) {
pq.insert(probs[i]);
records[i] = probs[i]; // records = {.09, .12, ...}
}
for(int i=0; i<2*len_probs-1; ++i)
codes[i] = 0;
for(int j=len_probs; j<2*len_probs-1; ++j) {
float el_left = pq.popRoot();
float el_right = pq.popRoot();
float new_el = el_left + el_right;
pq.insert(new_el);
records[j] = new_el;
for(int flag=0, i=j-len_probs; i<j; ++i)
if(codes[i] == 0) // avoid assignment el that not in HeapTree/PrioratyQueue
if(el_left == records[i]) {
codes[i] = j;
if(++flag == 2) break;
}
else if(el_right == records[i]) { // avoid el_right same to el_left
codes[i] = -j;
if(++flag == 2) break;
}
}
cout << "codes = [";
for(int i=0; i<2*len_probs-1; ++i)
cout << codes[i] << ", ";
cout << "]" << endl;
delete[] records;
delete[] codes;
}若待求结果依赖子问题(即各子问题之间不独立),贪心法难以求解全局最优;同理,分治法将做许多冗余工作,重复地解决公共子问题。动态规划方法要寻找符合“最优子结构“的状态和状态转移方程的定义,在找到之后,这个问题就可以以“记忆化地求解递推式”的方法来解决。
最优子结构:
在定义状态时,一定要定义成与数据索引相关的子问题(而非与数据量相关),这样就能在原始数据上设置固定围栏,执行有范围的拉网搜索,进而得到围栏内的最优解;然后借由最优子结构,通过记忆化地求解递推式,便可得到全局最优。
F[k]来表示区间[1,k]上的最优解,然后通过状态转移计算出[1,k+1]上的最优解,逐步扩大线性范围,最终求得[1,N]上的最优解。如最长单调子序列、小朋友过桥。F[m][n]来表示区间[1,m]和[1,n]上的最优解,如最长公共子序列。d[i][j]来表示区间
[i, j] 上的最优解,然后通过状态转移计算出 [i+1, j] 或者 [i, j-1]
上的最优解,逐步缩小区间的范围至终止状态,然后反向推理(递归自动实现),最终求得
[0, N-1] 的最优解。如最小插入回文串。select[i][j]来表示做01规划时做到第i件物品且消耗容量j时获得的最大收益。如01背包问题。当不将物品放入背包也会出现容量损失时,问题便不再是离散的01规划问题,即不再是背包模型,这种问题一般需用回溯进行求解。如小偷偷商店问题。
只须推得递推式,并确定停止条件即可,无须考虑繁琐的内部细节,计算机会在你定的条框下自动解决。
借用快排思想,时间复杂度为 \(\mathcal{O}(n)\) ,对于没有运行内存限制的情况是速度最快的解决方案。
将前 K 个数构建最小堆,并在内存中维护该最小堆(对于后 n-K 个数,若大于最小堆的堆顶则删掉堆顶并将该数插入堆中,否则忽略,如此遍历后得到的最小堆即为前 K 大的数),对于有运行内存限制的情况为最佳解决方案,时间复杂度为 \(\mathcal{O}(n \lg k)\) 。