
相似匹配就是图像检索的实现,常用于相似人脸检测,以图搜图等场景。
在数据充分,标签少的情况下,可将相似匹配问题转换为分类问题:首先使用分类模型(如 VGG)来训练出人脸特征指纹提取器,然后将特征指纹存放到数据库中,检索时使用kNN算法来检索出最接近的图像。
当每个类别中的数据集不够多时,特征提取器容易过拟合,Siamese 网络(左右两个网络共享权重)解决了该问题:

2-channel 网络是 Siamese 的进化版,它将提取特征和比较特征都放在一个网络中做,精度提高了但无法像Siamese一样将特征指纹存放到数据库中任意检索,实用性差:

为了加快在图像在数据库上的检索,在 VGG 后面接入一个降维层,降维为128维的特征哈希。建立索引时,将图像集的特征指纹,和特征哈希(特征哈希都按照四舍五入的原则转化为01编码就可以了)都存放到数据库中;检索时先检索特征哈希相同的图像,然后再在这少量的图像中执行kNN算法,从而大大提高了搜索的速度
名词:目标识别与目标检测不同,目标检测只分两类,即是物体与不是物体。
RCNN
SPP-Net
Fast-RCNN
Faster-RCNN
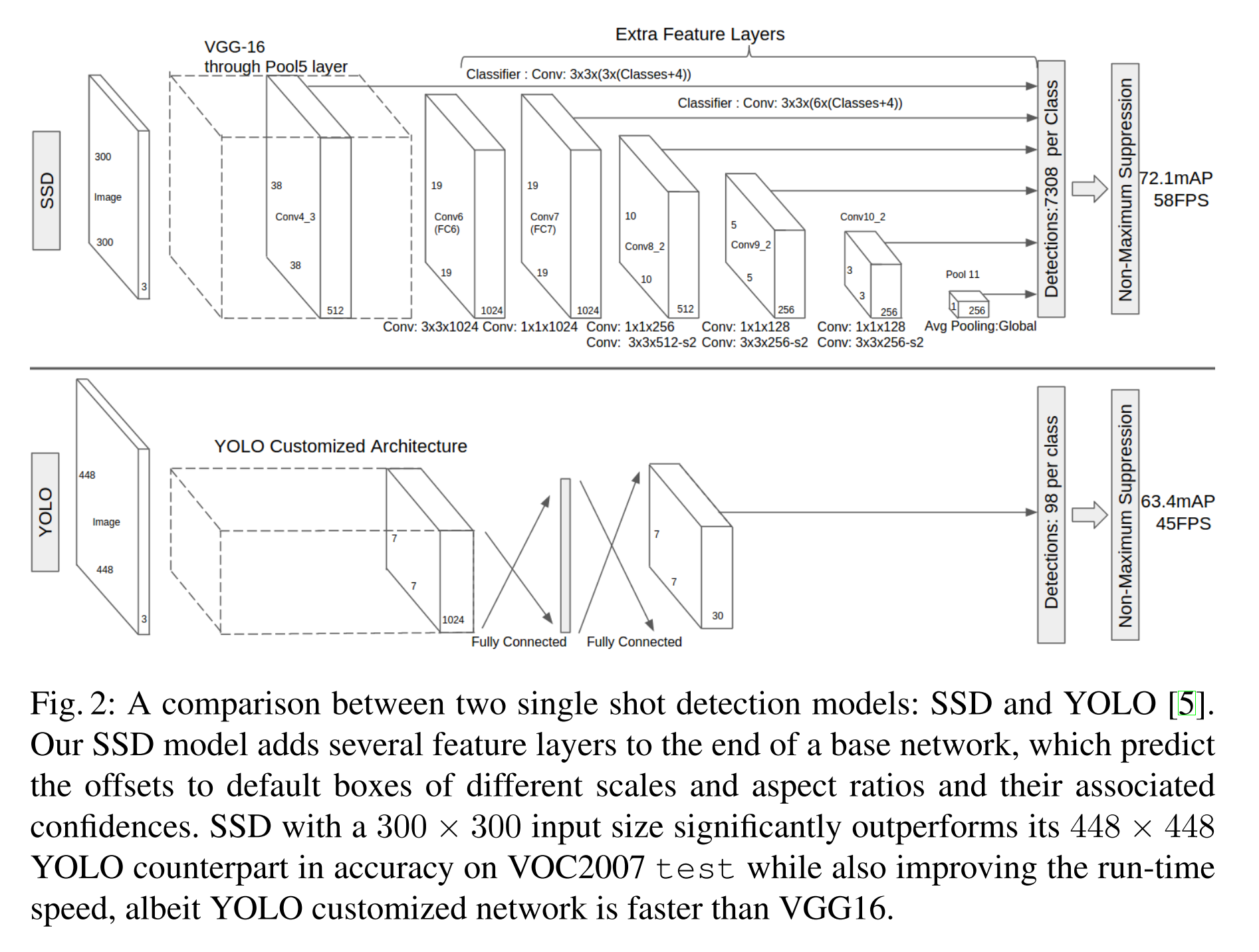
YOLO:第一个End-To-End的目标定位的模型,检测速度较快,不过精度较低;YOLO将图像统一到448x448的尺寸中,然后输入到预训练好的GoogleNet中得到14x14x1024的数据,然后接入4个卷积层和2个全连接层,得到7x7x30的数据输出;7x7x30代表的是,整个图像分为7x7共49个区域,每个区域包括2个bounding box(图中黄色实线框),bounding box的信息有(x_center,y_center,w,h,confidence),剩余的20维度信息就是20个分类的概率信息。

SSD:将 RPN 网络直接将多分类和位置精修都做了,不再需要 Fast-RCNN 网络的参与;另外,对于每个 anchor 点,不仅连接最近一个卷积层的信息,还连接前面一个卷积层的信息,甚至是第一个卷积层的信息,这样就能解决小物体识别的问题了。
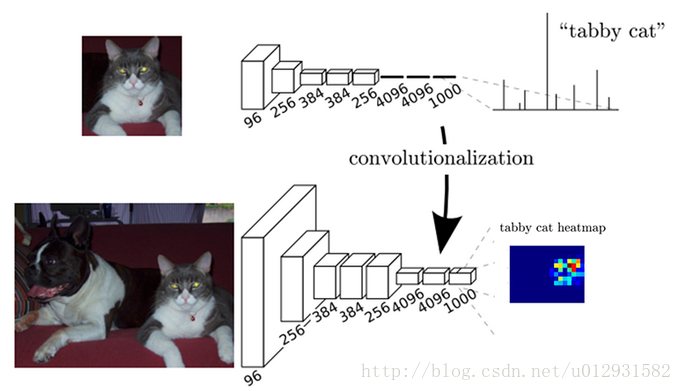
FCN:FCN与CNN之间的区别就是把最后几层的全连接层换成了卷积层,这样做的好处就是能够进行像素级分类;在前面几层卷积层,分辨率比较高,像素点的定位比较准确,后面几层卷积层,分辨率比较低,像素点的分类比较准确,所以为了更加准确的分割,需要把前面高分辨率的特征和后面的低分辨率特征结合起来。
FCN的缺点也很明显,首先是训练比较麻烦,需要训练三次才能够得到FCN-8s,而且得到的结果还是不精细,对图像的细节不够敏感,这是因为在进行decode,也就是恢复原图像大小的过程时,输入上采样层的label map太稀疏,而且上采样过程就是一个简单的deconvolution;其次是对各个像素进行分类,没有考虑到像素之间的关系,忽略了在通常的基于像素分类的分割方法中使用的空间规整步骤,缺乏空间一致性。
FCN进行upsampling的方法就是对feature map进行反卷积,然后和高分辨率层的feature map相加。
U-Net:U-net 是基于FCN的一个语义分割网络,适合用来做医学图像的分割;Unet进行upsampling的方法和FCN一样。
SegNet:SegNet 是一个 encoder-decoder 结构的卷积神经网络;SegNet的upsampling过程,就是把feature map的值通过之前保存的max-pooling的坐标映射到新的feature map中,其他的位置置零,进行upsampling的方法和DeconvNet一样。
Deep-Lab
DeconvNet:DeconvNet 是一个 convolution-deconvolution 结构的神经网络;DeconvNet进行upsampling的方法就是进行unpooling,就是需要根据之前pooling时的位置把feature map的值映射到新的feature map上,unpooling 之后需要接一个反卷积层。
Mask-RCNN
AE:AE可以用来做去噪,AE输入的是经过噪音污染后的图像,输出的是原来的图像,经过多轮训练后,AE就学到了特定噪音污染的去噪处理,但是,这种方法只对相当有规律的噪音有效。
pix2pix:pix2pix其实是cGAN的图像版本,在已经有一一对应的标注样本数据下,pix2pix能学习到输入图像到输出图像的映射。
pix2pix的主要亮点在于它的生成网络使用的是U-Net结构,一个能很好地重用低层特征和高层特征的结构;判别网络就是简单的四层卷积层。
CycleGan:CycleGAN是pix2pix的更进一步,输入的样本不再需要是一一标注的,只需要两类样本就可以了,网络会自己寻找到它们之间的映射。例如,我有一堆苹果的图片和一堆橙子的图片,我希望找到苹果图片转换为橙子图片的映射。但是我手上并没有苹果和橙子的一一对应映射对,是无法用pix2pix来训练的。
CycleGAN的思路是通过建立两个GAN网络来实现的,其中有个巧妙的loss设计是,两层映射以后必须要映射回自己本身。
CNN+multi-task:让CNN改为Mutlitask学习,一个输入(图像),多个输出(第一个字的分类,第二个字的分类等等);只是这样就只能让应付输出数字个数固定的场景。
LSTM+CTC
CTPN+CRNN:首先,CTPN网络是文字检测网络,网络首先通过VGG提取特征,然后经过双向lstm,生成anchor box(相当于Faster-RCNN的RPN网络,不过多了lstm的那一层),使用nms重叠的文本框,并将相邻的文本框以特定的规则合并起来,就能得到一个大的文本框。在这里CTPN已经能够提取出一个个的文本框了。然后,CRNN就是CNN+RNN+CTC的合并方法了,就是在之前的LSTM+CTC的基础上加上了CNN预提取特征,识别率目前是最高的。
