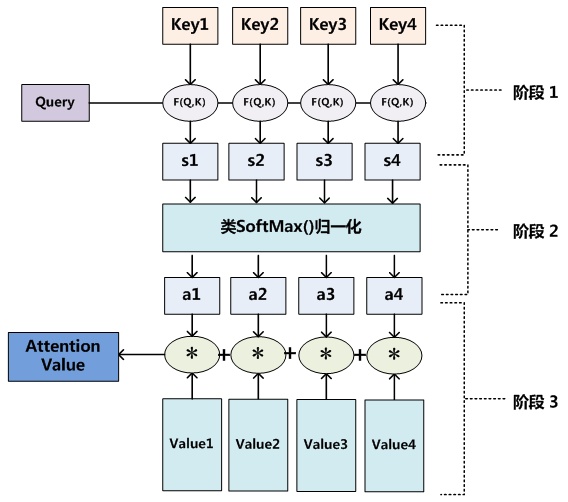
其中query为目标语言端的h,key和value也为源语言端的两个不同空间的h,通过点积等方法计算相似度后得到该时刻t的a,将value与a做加权求和后得到attention value,即得到该t时刻目标语言端的h。
简单来说就是将当前时刻的目标语言与源语言的各个向量求个相似度,用来对源语言的各个向量做加权求和,从而通过attention机制实现源语言与目标语言的对齐。
attention可以有很多种计算方式: 加性attention、点积attention,还有带参数的计算方式。
以点积attention为例:
而每一层线性映射参数矩阵都是独立的,所以经过映射后的Q, K, V各不相同,模型参数优化的目标在于将q, k, v被映射到新的高维空间,使得每层的Q, K, V在不同抽象层面上捕获到q, k, v之间的关系。一般来说,底层layer捕获到的更多是lexical- level的关系,而高层layer捕获到的更多是semantic-level的关系。
\[ loss = \{^{-\alpha (1-y')^\gamma \log y', y=1} _{-(1-\alpha)(y')^\gamma \log (1-y'), y=0}. \]
对于二阶目标检测算法,有特征重采样过程,可在该过程中通过固定正负样本比例或在线困难样本挖掘(OHEM)使得前景和背景相对平衡;而一阶目标检测算法最多只能在数据集上做固定正负样本比例的处理,训练会被大量易分样本主导,导致模型难以收敛至更优解,focal loss 用 Boost 的方法解决了这个问题。
经过 BN 层后,使得输出的均值与方差不再与前面的网络参数有复杂的关联依赖,而只由 BN 层的参数 \(\beta , \gamma\) 决定,故前面的网络参数是否学好并不影响后面 BN 层参数 \(\beta , \gamma\) 的学习,若前面的网络参数尚未学好,已经学好的 BN 层参数 \(\beta , \gamma\) 的存在,会使得最近一层的网络参数更快地朝好的方向发展,进而一步步反传使得所有网络参数达到最优,而不必费心地去考虑网络参数如何初始化最好。
BN 层使得应处于激活函数饱和区的神经元处于饱和区,应处于激活区的神经元处于激活区,即无论网络参数如何,BN 层仍可使得信号进行有效的传播,结合对参数的正则化,学习到的权重便不会过高或过低,从而从根本上解决了因 w 的大小而导致的梯度爆炸或消失问题。
容许较高学习率的原因:
对于通用格式 conv + BN + ReLU 中的 conv 层不加 bias 是因为 BN 已有 bias 功能?:
faster-rcnn 中的 BN 怎么操作的?:
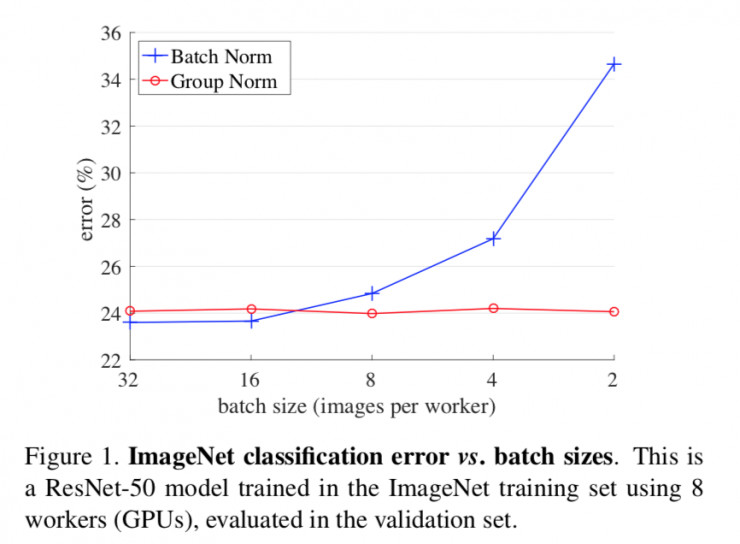
减了对初始化参数的依赖,那么迁移学习的必要性:?
https://docs.google.com/presentation/d/18MiZndRCOxB7g-TcCl2EZOElS5udVaCuxnGznLnmOlE/pub?slide=id.g963e5b4287fb24d_5