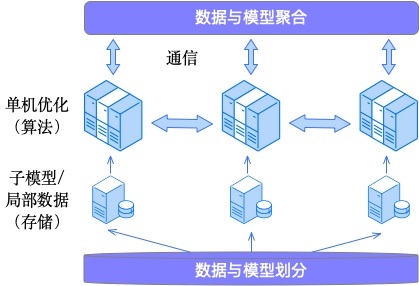
分布式机器学习,研究的是如何使用计算机集群来训练大规模机器学习模型。
为什么需要:
相应的方法:
由此引出分布式机器学习的3个主要topic:存储、通信、算法。
存储决定了特征支持的规模可以有多大,因为存储往往是这个场景的一个硬限。比如sparse参数,通过hash分桶到各个server,各个server内分shard,进一步提升性能。涉及到相关的技术主要包括:hash、异构存储、存储压缩等。这块主要是工程上的技术,暂不展开。
通信决定了训练效率的上限,基本上无论是CPU分布式还是GPU分布式系统,在大模型训练上的瓶颈都会是稀疏参数的通信效率上。
这块虽然也主要是工程上的技术,但这块和算法有千丝万缕的关系,所以还是需要了解个基础。
工程上,如何降低sparse模型通信量,减少hash查找,如何降低dense模型通信量,如何处理pull&push的顺序关系(是否需要同步等),如何处理通信长尾问题,是关键问题。一些做法如下:
算法上,多机、多线程如何协作才能得到最优模型是关键问题,主要包括通信的内容、拓扑结构、步调和频率。
Map操作完成数据分发和并行处理,Reduce操作完成数据的全局同步和聚合。
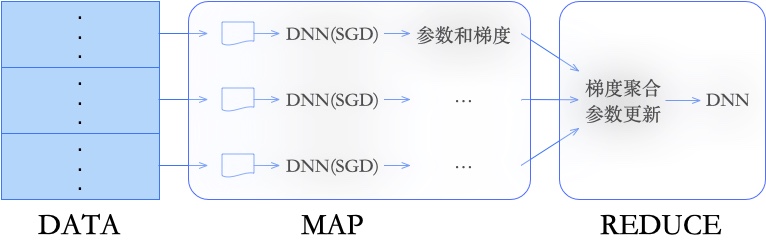
因为运算节点和模型存储节点没有很好的逻辑隔离,故做不到计算梯度的同时并行更新模型参数,因此只能支持同步的通信模式,即:只有在所有Mapper任务全部完成后,才能进入Reduce过程,反之亦然。
参数服务器(parameter server)把工作节点和模型存储节点在逻辑上区分开来,各个工作节点之间可以不用时刻保持同步,计算比较快的节点可以不用等待计算比较慢的节点,从而取得更高的加速比。
PS包含了两种角色Worker和Server,其中Worker是计算节点,Server负责参数的存储和更新。
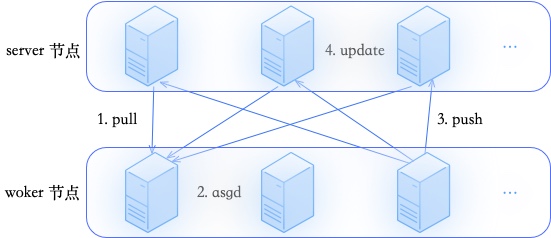
一般情况下,worker训练是多线程的,每个训练线程之间都是数据并行的。训练一个mini-batch的流程是:
pull:训练线程从server端拉取DNN小模型及当前batch的所有feasign对应的embedding(同步)
asgd:训练线程进行前向、反向计算,得到所有参数的梯度
push:训练线程将当前batch计算得到的梯度,发给server(异步)
update:server接受训练线程发来的梯度,并使用用户指定的优化算法(AdaGrad、Adam等)更新本地参数
细节可参考:https://weisong.space/blog/posts/机器学习_神经网络.html#:~:text=Downpour SGD
算法决定了稀疏参数的学习效果,高低频识别(embedding大小设计)、特征正则化(避免过拟合)、特征空间限制(特征工程)、流式online learning(FTRL等)等等话题都可以归到这里。
也可以叫稀疏化算法,或者feasign维度的特征重要度筛选。
推荐系统的online learning背景下,其embedding存在以下几个问题:
先不考虑工程上导致的问题(存储、耗时),在算法上,会导致模型过拟合(特征量级上涨 -> 模型复杂度上涨)。
故需要采用各种稀疏化算法来进行正则化,与NLP、CV领域的正则化方法不同(基于权重和梯度来进行的,如L1正则、模型剪枝),推荐领域对稀疏特征依赖较强,且稀疏特征的高低频的置信度差异比较大,故推荐领域常见的稀疏化方法是基于特征频次来进行的(特征准入、特征退场)。
【训练过程中的准入:哪些feasign加入mf】
创建feasign的时候embedding只有lr一维,随着迭代,根据show/click判断要不要新增mf(为什么保留lr:传统情况只有mf,当满足特征准入时,产生mf加入模型训练;那么在特征未准入时只累积show/clk,为弥补这些折损样本的gap,在特征准入前会训练一个固定1维的embedding,即lr,从而弥补特征准入前的样本gap。) \[ \begin{align*} (show - clk) * nonclk\_coeff + clk * clk\_coeff &\ge create\_threshold \\ (1 - ctr) * nonclk\_coeff + ctr * clk\_coeff &\ge \frac{create\_threshold}{show} \end{align*} \] 定义 (show - clk) * nonclk_coeff + clk * clk_coeff 为特征重要度(下面简称show_clk_score),一个粗略的理解便是:特征重要度高于某个阈值后,便准入(Probabilistic Feature Inclusion)。
通过具体例子来详细理解: \[ (1 - ctr) * 0.1 + ctr * 1 \ge \frac{10}{show} \]
【部署上线过程中的准入:哪些特征的embedding save到模型中】
delta模型:同时满足下面3个条件,才会将大模型配送到线上
base模型:同时满足下面3个条件,才会将大模型配送到线上
时机:save完base模型后。
退场策略:满足以下任一条件,该feasign便会从内存中删除。
1、feasign再未出现的天数:unseen_days > delete_after_unseen_days。
2、后验特征重要度:show_clk_score < delete_threshold,假设取为0.3,那么直观理解便是,只有show<3时,特征后验CTR低于某个阈值才会退场。